为什么我试了三周 Claude Code,反而不再把它当 Cursor 用
Claude Code 跟 Cursor 最大的差别,不是模型,也不是谁更会写代码,而是它逼你把一次编码任务变成可计划、可执行、可验证的闭环。

我第一次认真用 Claude Code,不是因为它又出了什么新模型。
原因很土:一个 Go 项目里有几处历史代码,我懒得再一层层翻。放在 Cursor 里问,当然也能问;但我真正想要的不是“解释一下这段代码”,而是让它自己去读目录、找调用链、列改动计划、改完跑测试,再把证据交回来。
这件事用三周之后,我对 Claude Code 的看法变了。
它不是 Cursor 的终端版。
如果你把它当成另一个聊天框,用几句自然语言让它帮你补函数、改变量名、解释报错,大概率会失望。Cursor 这类编辑器内工具在这件事上已经足够顺手。Claude Code 真正有意思的地方,是它更像一个坐在终端里的执行者:能读文件,能跑命令,能改代码,也能被测试和构建当场打脸。
这也是它跟 Cursor 最大的差别。
Cursor 更像一个会写代码的编辑器伙伴。Claude Code 更像一个可以被你派工的命令行同事。
同事这个词很关键。你不能只对同事说“把这个项目优化一下”,然后走开。你要给范围、约束、验收标准,还要看它最后拿什么证明自己没乱改。
最大的区别不是模型,是模式
很多人比较 Claude Code 和 Cursor,第一反应还是看模型、上下文、价格、额度。
这些当然重要,但不是最先该看的。
真正决定体验的,是你把 AI 放在什么位置。
Cursor 的入口在编辑器。你一边看文件,一边问它为什么这样写;你选中一段代码,让它改;你把报错贴进去,让它解释。它适合“边看边聊”。
Claude Code 的入口在终端。它面对的是一个项目目录、一组命令、一堆文件,以及你给出的目标。它适合“派一个任务,让它在项目里跑出结果”。

所以我现在不会问“Claude Code 和 Cursor 谁更强”。这个问题太粗。
我会问另一个问题:这次任务,我是需要一个编辑器旁边的对话助手,还是需要一个能自己跑完一段工作流的终端执行者?
前者用 Cursor 很自然。后者,Claude Code 更顺手。
很多误用都卡在这里。你拿 Claude Code 做很小的补全,觉得它笨重;你拿 Cursor 做一大段跨文件重构,又会觉得来回确认、复制上下文、跑命令很割裂。工具没错,是任务放错了入口。
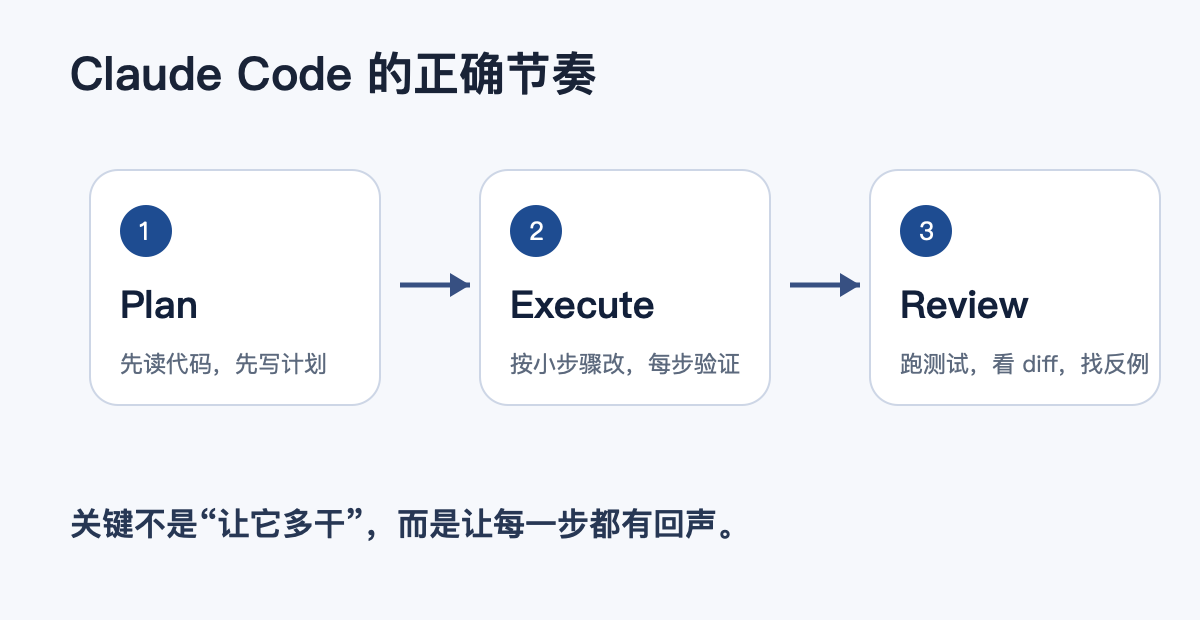
我后来固定成一个节奏:Plan → Execute → Review
Claude Code 最容易翻车的用法,是一上来就让它改。
尤其是 Go 后端项目。一个登录问题可能牵到 middleware、session、cache、数据库、测试夹具;一个接口字段调整,可能穿过 handler、service、repo、DTO、Swagger、单测。你让它直接“修一下”,它当然会动手。问题是它动手太快,你还没确认方向。
我现在更愿意把任务拆成三段。
第一段,只计划,不写代码。
| |
这一步的价值不是让 Claude 表演“思考”。而是先把它看到的东西摆出来,给你一个能审的计划。
第二段,按计划执行。
| |
第三段,做交付前 Review。
| |
这个流程听起来慢,其实更快。
因为 AI 编码最贵的成本,不是它写代码慢,而是它写错方向之后,你要花半小时把它改过的东西一行行捋回来。
别让 AI 一路狂奔。让它每一步都有回声。
CLAUDE.md 不是许愿池,是项目说明书
Claude Code 用久了,你会很快遇到另一个问题:每次都要重复交代项目习惯。
比如:
- 这个 Go 项目用
make test,不是直接go test ./...; - 生成文件不要手改;
- 数据库 migration 合并后不能改旧文件,只能新建;
- handler 里不要塞业务逻辑;
- 新增接口必须补集成测试。
这些话如果每次都粘给它,既浪费上下文,也容易漏。
这时就该写 CLAUDE.md。
我更愿意把它当成“项目说明书”,而不是“AI 记忆”。它应该短、硬、具体,最好每条都能被执行或验证。
比如:
| |
不要把 CLAUDE.md 写成团队文化手册。它不是给人看的 onboarding 文档,而是给一个会执行命令的模型看的项目约束。
越具体,越有用。
Slash Commands 和 Skills:别把所有东西都塞进上下文
CLAUDE.md 适合放“每次都要知道”的东西。
但有些流程不是每次都用。比如 code review、发版检查、迁移组件、排查线上告警。这类内容如果全塞进 CLAUDE.md,最后只会把上下文撑胖,还让模型分不清哪些规则是常驻的,哪些只是某个场景要用。
这类流程更适合做成 Skill 或 slash command。
比如给项目加一个 .claude/skills/review-diff/SKILL.md:
| |
以后你不用每次复制一大段 review prompt,只要在需要的时候调用它。
这里的取舍很简单:常驻事实放 CLAUDE.md,偶发流程放 Skill。不要把一个工具用成杂物间。
上下文不是仓库,不能什么都往里扔。
MCP 的价值,不是“工具越多越强”
我一开始对 MCP 的兴趣也很朴素:能不能少复制粘贴?
真实开发里,问题很少只在代码里。一次线上报错可能在 Sentry,一条需求可能在 Linear,一段上下文在 Slack,相关 PR 在 GitHub,真实数据结构在 PostgreSQL。你当然可以自己打开五个网页,再把信息贴给 Claude。
但这其实是在替 AI 搬砖。
MCP 的价值,是把这些外部系统变成 Claude Code 能调用的工具。它可以读 issue、查 PR、看日志、连数据库、跑浏览器验证。对一个终端里的执行者来说,这非常关键:它不再只靠你口述世界,而是能碰到一部分真实世界。
但我不建议一上来就接一堆 MCP。
工具太多也会吃上下文,还会扩大风险面。尤其是带写权限的 GitHub、数据库、工单系统,别为了“酷”就全局打开。
更稳的做法是:
- 团队共享的、低风险的工具,放到项目级
.mcp.json; - 个人 token 用环境变量,不要写死;
- 只给特定 subagent 用的工具,不要全局挂;
- 能只读就先只读,写操作再单独授权。
MCP 不是插件市场。
它是把 AI 放进真实工作流时,必须认真管理的权限边界。
Hooks:把“我希望”变成“它必须”
CLAUDE.md 和 Skill 解决的是上下文问题,Hooks 解决的是另一件事:确定性。
这两者不要混在一起。
你在 CLAUDE.md 里写“修改 Go 文件后要跑 lint”,它大概率会照做。但大概率不是工程约束。只要上下文变长、任务变复杂、模型判断错优先级,它就可能忘。
如果这件事真的不能忘,就应该交给 Hook。
比如编辑后自动格式化、执行危险命令前拦截、停止前跑测试、修改受保护目录时要求确认。这些都不应该靠模型自觉。
我会把规则分成两类:
- 需要模型理解的,写进
CLAUDE.md或 Skill; - 不需要模型理解、只需要稳定执行的,交给 Hook。
举个例子,“不要修改已合并 migration”这句话,写进 CLAUDE.md 可以提醒它。但如果你的项目真的很怕这件事,最好再加一个 PreToolUse 或编辑后检查:只要碰到对应目录,就直接拦下来。
这就是 Claude Code 和普通聊天工具最大的区别之一。你不只是给它提示词,你可以给它一套执行环境。
但 Hook 也别乱加。
每一个 Hook 都会改变工作流。加得太多,Claude 还没开始干活,就被一堆脚本来回打断;加得太少,又全靠模型记忆。我的经验是,只给三类事情上 Hook:安全边界、格式化这类机械动作、停止前验证。
别把纪律交给提示词。
提示词会忘,脚本不会。
还有一个容易忽视的动作:让它先写失败测试
如果你做的是 bug 修复,尤其是后端 bug,我会强制 Claude 先复现。
不是因为 TDD 听起来高级,而是因为这一步能把任务从“你觉得修好了”变成“测试确实抓到了问题”。
可以这样给它:
| |
这句话非常值钱。
它能防住一种常见幻觉:Claude 看懂了现象,也写了一个看起来合理的修复,但其实没有碰到真正的失败路径。最后它告诉你“已完成”,你一跑线上同类场景,问题还在。
对 Go 后端来说,失败测试还有一个好处:它会逼 Claude 找到正确的层次。问题到底在 handler 参数解析,还是 service 状态流转,还是 repo 事务边界?测试写在哪一层,往往已经暴露了它对问题的理解。
修 bug 之前先让它复现。
这不是仪式感,是防跑偏的刹车。
长上下文真正要管,不要等它自己 compact
Claude Code 很容易让人产生错觉:既然它能一直读、一直改、一直跑,那我是不是可以把一个大任务从头丢到尾?
最好别这样。
官方最佳实践也反复强调上下文窗口是核心约束。上下文越长,越容易混入过期计划、失败尝试、无关日志。等到自动 compact 发生时,很多细节已经不可控了。
我现在做长任务,会主动留几个“刹车点”:
第一,任务拆小。一次只做一个可验证改动,不要让它同时重构、修 bug、补测试、改文档。
第二,阶段结束就让它总结当前状态,必要时 /compact,只保留计划、决策、diff 摘要和失败测试。
第三,大阶段完成后直接 /clear,用 git commit 或进度文件把现场保存下来,而不是让旧上下文一直挂着。
第四,复杂探索交给 subagent 或新会话,不要把大量文件阅读都堆在主会话里。
这件事很反直觉:你越想让 AI 长时间连续工作,越要主动给它切段。
长上下文不是护城河,有时是泥潭。
那到底怎么跟 Cursor 搭配?
我的答案不复杂。
如果你主要是在写前端、看 UI、调交互、边看代码边和 AI 讨论,Cursor 仍然非常舒服。它的强项是把代码、对话、上下文放在同一个视觉空间里。
如果你要处理后端项目里的跨文件任务、测试驱动修复、批量重构、脚本化验证、CI/CD 前检查,Claude Code 的终端入口更合适。因为这些任务最后都要回到命令输出:测试过没?lint 过没?diff 长什么样?构建有没有失败?
我现在的分工大概是:
- 看代码、理解模块、临时改一小段,用 Cursor;
- 要计划、要执行、要验证闭环,用 Claude Code;
- 两边都能做的任务,看入口:我当时是在编辑器里,还是在终端里。
不要把工具选型搞成信仰问题。
真正应该选的,是任务入口。
给 Go 后端开发者的一套最小用法
如果你刚开始试 Claude Code,我建议别先研究一堆花活。先把下面这套跑顺。
第一步,在项目根目录运行 /init,生成或整理 CLAUDE.md。别写太长,只写项目结构、测试命令、代码边界和禁止事项。
第二步,复杂任务先开 plan mode:
| |
第三步,给任务时永远包含五件事:目标、范围、约束、验证命令、停止条件。
| |
第四步,改完必须让它交证据,不要只听“完成了”。
| |
第五步,任务结束看 diff。AI 写完不是结束,diff 过眼才是结束。
这套流程并不酷,但很管用。
你不是在找一个更聪明的自动补全。
你是在训练一个能被验收的工作流。
最后说一句实话
Claude Code 用得好,会让你感觉自己多了一个能干活的同事。
但它也会暴露一个问题:很多开发者其实没有清晰地描述过自己的工作流。测试怎么跑、哪些文件不能改、什么叫完成、什么风险必须停下来问人,这些东西以前靠经验和默契,现在必须写清楚。
所以 Claude Code 真正逼你的,不是学一个新工具。
是把脑子里的工程习惯,变成可执行的规则。
如果你只想要一个随叫随到的代码补全,Cursor、Copilot 已经够用。
如果你想让 AI 真的参与一次后端任务,从计划到执行再到验收,Claude Code 值得试。但别把它当魔法,也别把方向盘整把交出去。
给它任务,给它边界,给它测试。
然后看它拿什么证据回来。
如果你也在用 Claude Code 或 Cursor,可以关注我。后面我会继续写一些更贴近真实项目的 AI 编程工作流:不是功能清单,而是哪些地方真的省时间,哪些地方只是看起来很爽。