Go 数组为什么这么硬?因为它要把边界写进类型里
Go 数组不是 slice 的过时底层细节。它把长度、值语义、比较能力和固定布局都写进类型里,牺牲弹性,换来边界清楚和编译器可证明的信息。
同样是复制,一个 [32]byte 的 hash 往往很安全,一个 struct 里的 [4096]int 却可能把性能拖得很难看。
这不是 Go 数组“好不好用”的问题,而是你有没有把它当成正确的东西。
很多 Go 开发者平时几乎不直接写数组。业务列表用 slice,字典用 map,缓冲区也经常一上来就是 []byte。于是数组很容易被误解成 slice 背后的旧零件:知道有这么个东西,但最好别碰。
这个判断太粗了。
数组在 Go 里不是为了替代 slice 做动态集合。它的价值恰恰在于“不灵活”:长度固定、类型固定、赋值复制、元素可比较时整体可比较。它把一块数据的形状写死,让函数边界、类型系统和编译器都少猜一点。

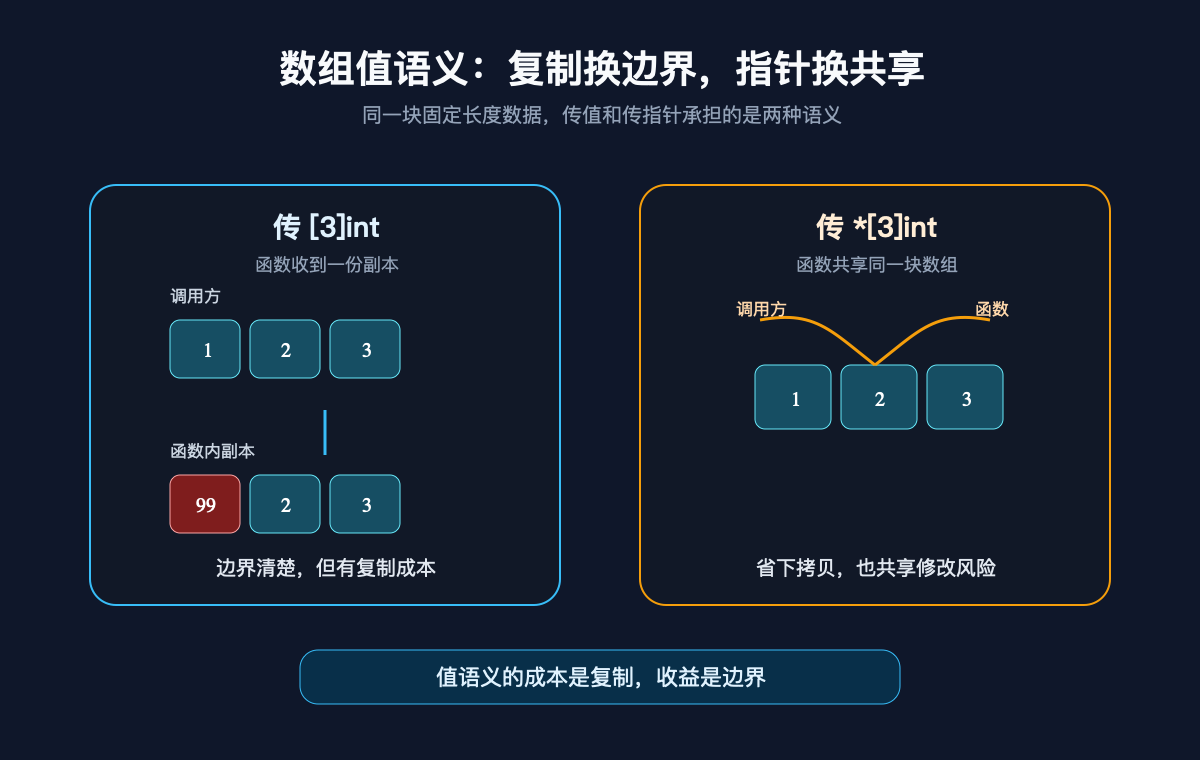
数组是值,长度是类型
Go 的数组变量代表整个数组,不是指向第一个元素的地址。
这句话听起来像语法点,实际影响很大。你把一个数组赋给另一个变量,复制的是整个数组;你把数组传给函数,函数收到的也是一份数组值。除非你显式传 *[N]T,否则函数里改不到调用方那份数组。
| |
返回的第一份还是 [1 2 3],第二份才是 [99 2 3]。
这和 C 很不一样。C 里数组在很多表达式上下文会退化成指向首元素的指针,函数参数里写数组也经常变成指针语义。方便是方便,代价是边界信息丢了。函数签名看起来像接收数组,真正拿到的却是一段地址,长度要靠另一个参数或约定补上。
Go 没有走这条路。
[3]int 和 [4]int 是两个不同类型。函数写 func f(a [4]int),就只能接 [4]int。这对写“任意长度列表”的 API 很不友好,但对固定协议、固定摘要、固定字段来说,反而正好:长度不是注释,不是文档承诺,而是类型的一部分。
数组的硬,不是缺点本身;把它用在动态集合上,才会变成缺点。
值语义的收益是边界,成本也是边界
数组按值复制,第一反应很容易是:那不就慢吗?
要小心这个结论。慢不慢,先看数组多大、怎么传、语义上是不是一个“值”。
sha256.Sum256 返回的是 [32]byte。这很合理。一个 SHA-256 digest 天生就是 32 字节的固定值,它不是一个会变长的字节列表。用 [32]byte 表达它,能直接比较,也能直接做 map key。
| |
如果这里换成 []byte,事情反而麻烦。slice 不能直接比较,也不能直接做 map key。你要么手动比较,要么转成 string,要么引入额外封装。不是不能做,而是语义绕了一圈。
数组可比较也不是孤立语法。Go 的规则是:元素类型可比较,数组就可比较;比较时按索引顺序逐元素比较。[32]byte 可以比较,是因为 byte 可比较。[2][]int 就不行,因为 slice 不可比较。
所以小的、固定的、语义上完整的数据,数组值语义通常很舒服。
真正要警惕的是大数组跨函数频繁传递。
研究素材里在 Apple M1 Pro、Go 1.25.4 上跑了一个 benchmark:函数只读 [4096]int 的首尾两个元素,按值传参平均约 774.22 ns/op;传 *[4096]int 平均约 0.94 ns/op。另一个 [1024]int 求和例子,按值传参平均约 586.14 ns/op,传指针平均约 329.10 ns/op。
这些数字不能拿去当普适常数,但趋势很清楚:没有堆分配,不代表没有复制成本。0 B/op 只能说明没有分配,不说明 CPU 没有搬那块数组。
值语义的成本是复制,收益是边界。
指针省下的是拷贝,增加的是共享状态。传 *[4096]int 很快,但你也把“谁能改这块数据”的边界交给了约定。该不该这么做,不是性能口号能回答的,要看这块固定长度数据到底应该被当成值传递,还是被多处共享。
数组适合表达固定契约,不适合假装弹性
如果一个函数想接收任意长度的整数列表,参数应该是 []int。不要为了“更底层”强行写 [N]int。
Go 数组的真正场景通常不是“集合”,而是“固定形状”:
- hash digest:
[16]byte、[32]byte这种固定长度值; - 协议头:比如
Header [14]byte,长度就是协议契约; - 内联小字段:字段跟着对象走,而不是额外指向一块 backing array;
- 固定查表:长度是算法的一部分;
- map key:元素可比较时,整个数组可以直接做 key。
例如协议包可以这样表达:
| |
Header 是固定的,Body 是可变的。一个用数组,一个用 slice,语义正好分开。
这比一律 []byte 更诚实。Header 不会变成 13 字节或 15 字节,它不是动态列表。把它写成 [14]byte,调用者、维护者和编译器都知道这件事。
这里也要避免另一个过度宣传:数组内联在结构体里,不等于自动更快。结构体布局、padding、逃逸分析、缓存行为都可能影响结果。更稳的说法是:数组字段改变了数据的所有权和局部性,固定头部跟着对象走,而不是靠一个 slice header 指向别处。
这是设计边界,不是玄学性能。
编译器喜欢的不是数组,而是可证明的信息
很多性能文章喜欢把数组和“缓存友好”“编译器优化”绑在一起。方向没错,但容易讲过头。
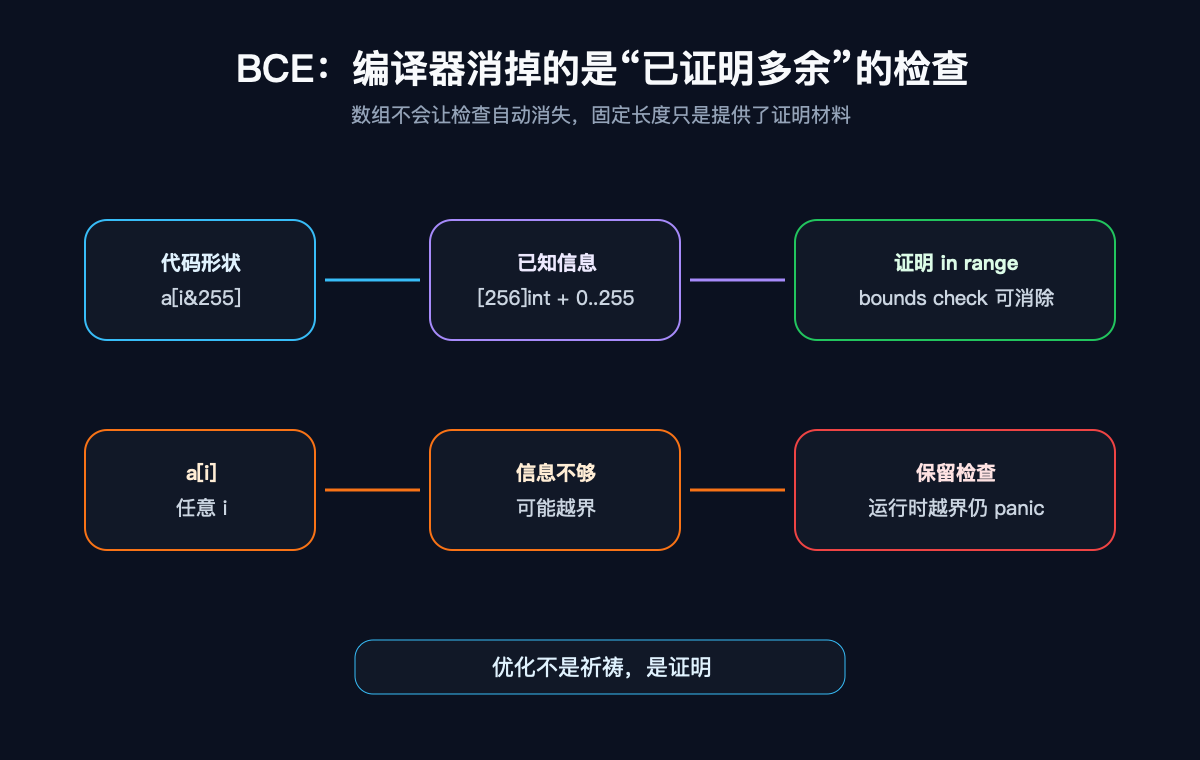
Go 有边界检查。用数组不等于没有边界检查。真正发生的是:在某些代码形状下,编译器能证明索引一定不越界,于是消掉不必要的 bounds check。这叫 bounds check elimination,BCE。
研究素材里有三个例子:
| |
i&255 的结果一定在 0 到 255 之间。对 [256]int 来说,当前 Go 1.25.4 编译器能证明它安全,所以这个访问没有出现在 BCE 诊断里。
但 a[i] 不行。任意 i 可能越界,检查还要保留。
s[i&255] 也不一定能消掉,因为 slice 的长度是运行时信息。i&255 只说明索引小于 256,不说明 len(s) 一定大于等于 256。
用下面的命令可以观察诊断:
| |
本机诊断里保留了 BCENeedsCheck 和 BCESliceUnknown 的检查,也在另一个 slice/array 转换例子里提示了 Found IsInBounds。这比一句“数组更快”有用得多。
优化不是祈祷,是证明。
还有一个边界要说清楚:不要把 Go 1.25.4 的数组写成“会触发通用自动向量化”。Go 编译器有 SSA 优化、intrinsics、memclr 等具体优化,SIMD 方向也在推进,但在 Go 1.25.4 下,把“数组会自动向量化”当成确定卖点,容易误导读者。
数组能给编译器更多固定信息,但编译器不会因为你用了数组就自动变聪明。
跟 C、Java、Rust 比,Go 的选择很克制
看其他语言,Go 数组的设计会更清楚。
C 的数组很接近机器,但函数边界上经常退化成指针,长度信息容易丢。它把控制权给了程序员,也把很多安全责任交给了约定。
Java 数组是对象,变量拿的是引用。使用体验统一,运行时也有边界检查,但数组变量不是整块值,长度也不是类型的一部分。
Rust 的 [T; N] 同样把长度放进类型里,同时又有所有权和 borrow checker 来约束 move、copy、borrow。它的类型系统更强,也更重。
Go 的做法介于中间:数组是值,长度进类型;要共享就传指针;要弹性就用 slice。它没有 Rust 那套完整所有权系统,也没有 C 那种隐式退化,而是把几种选择摆在代码表面。

这就是 Go 数组看起来“不顺手”的原因。它没有试图顺手。
它是在逼你区分三件事:
- 这是一块固定形状的值吗?用
[N]T。 - 这是一块固定形状但不想复制的存储吗?考虑
*[N]T。 - 这是任意长度的一段数据吗?用
[]T。
什么时候用数组,什么时候别用
可以用一个很实用的检查方式收尾。
如果长度是协议、算法或格式的一部分,数组值得考虑。比如 hash、UUID、固定头部、固定查表。你不是为了“更底层”用数组,而是因为长度本来就是契约。
如果你需要直接比较、需要做 map key,并且元素类型可比较,数组也很合适。map[[32]byte]T 比把 digest 转来转去更自然。
如果数组很小,语义上又确实是一个完整值,按值传递通常没问题。不要看到“复制”两个字就条件反射改成指针。
但如果数组很大,又频繁跨函数传递,就应该停一下。要么传 *[N]T,要么重新判断 API 是否应该接 []T。前者保留固定长度契约,但共享修改风险也更明确;后者表达动态视图,更适合通用输入。
最后,性能问题别靠想象。跑 benchmark,看 BCE 诊断,看逃逸结果。Go 数组给你的不是魔法,而是更清楚的边界。
slice 是给程序员的弹性,数组是给机器的确定性。
真正成熟的 Go 代码,不是到处用数组,也不是完全躲开数组,而是知道什么时候应该把长度、复制和边界写进类型里。