Go 里真正难懂的不是 slice,是它背后的数组
很多人把 slice 理解成动态数组,却忽略了 Go 真正的设计取舍:数组给机器确定性,slice 给程序员弹性,而大多数坑都藏在这两者之间。
一次 append,把原来的数据改坏了。
代码看起来很普通:从一个 slice 里切一段出来,往这段里追加一个元素。你以为只是改了新变量,结果回头一看,原 slice 里的某个位置也变了。
这类问题很烦,因为它不像空指针那样直接炸给你看。它更像一个安静的错:数据还在,长度也对,测试偶尔过,线上某个分支才露出一点不对劲。
很多人这时会说:slice 是引用类型。
这句话不算完全错,但太粗糙。粗糙到一定程度,就会害人。
Go 里真正值得理解的,不是“slice 是不是引用类型”,而是:数组负责装数据,slice 只负责描述一段数组。数组给机器确定性,slice 给程序员弹性。Go 同时保留这两个东西,不是语言设计多此一举,而是它不愿意把这两种需求混成一团。
理解这一点,后面的 append、扩容、子切片、内存保留,都会变得顺很多。
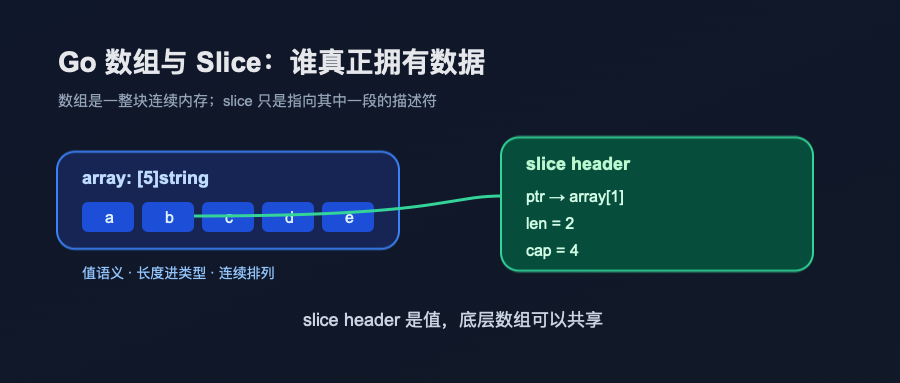
数组很硬,但这正是它的价值
Go 的数组不是“指向一串元素的地址”。数组变量代表的是整个数组。
[3]int 和 [4]int 是两个不同类型。长度进类型,元素连续排列,赋值和传参都会复制整个数组。这些特性放到业务代码里看,确实不够灵活:函数想接收任意长度的整数列表,不能写一个 [N]int 让 N 动起来;大数组传来传去,也会带来复制成本。
但站在机器这边看,数组非常舒服。
长度确定,布局连续,元素类型一致。编译器知道它有多大,CPU 也喜欢顺着连续内存往前读。很多时候,所谓“底层性能”,并不是某个神秘技巧,而是数据摆得足够朴素,机器不用猜。
所以数组不是 Go 里被 slice 淘汰掉的旧家具。它更像地基。
你日常很少把数组当动态集合用,不代表它不重要。恰恰相反,slice 的一切便利,都建立在底层数组这块“确定形状的钢板”上。
slice 不是数组,是一张小纸条
slice 本身并不装元素。
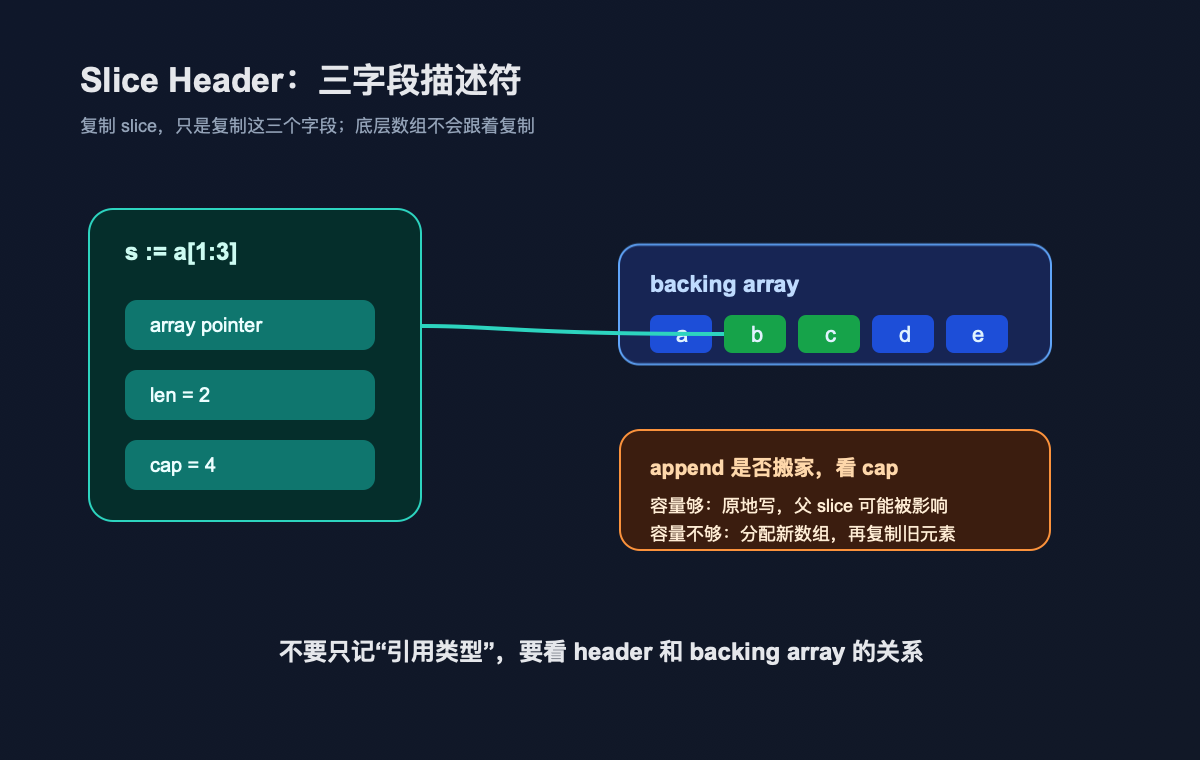
在 Go 1.25.4 的 runtime 源码里,slice 的核心结构就是三个字段:
| |
可以把它理解成一张小纸条:
array:从哪块底层数组开始看;len:现在能看到多少个元素;cap:在不换底层数组的前提下,最多能往后用到哪里。
这张纸条会被复制。函数传参时,复制的是 slice header,不是底层数组。两个 slice 变量可以各自有不同的 len,但指向同一块 backing array。
这就是 slice 好用的地方,也是坑开始的地方。
看一个最典型的例子:
| |
在本机 Go 1.25.4 上,素材里的示例输出是:
| |
child 原来看到的是 b, c。它 append 一个 X,为什么会把 parent 里的 d 改掉?
原因不在“引用类型”这四个字,而在 cap。
child := parent[1:3] 之后,child 的 len 是 2,但 cap 会从下标 1 一直算到 parent 末尾。容量还够,append 就不需要搬家,直接在原 backing array 后面写。于是 X 写到了原来 d 的位置。
这就是 append 最容易被误解的语义:
append 不是“一定新建”,而是“容量够就原地写,容量不够才搬家”。
如果你想让子切片 append 时不要碰到父 slice,可以用 full slice expression 限制 cap:
| |
输出会变成:
| |
第三个下标不是装饰,它是在告诉 Go:这段 slice 的容量到这里为止。再 append,就请换一块新数组。
扩容不是玄学,也不是永远 2 倍
很多旧文章会把 Go slice 扩容讲成一句话:小于 1024 翻倍,大于 1024 按 1.25 倍增长。
这句话现在不能直接用了。
按 Go 1.25.4 的 nextslicecap 源码,阈值是 256:旧容量小于 256 时,目标容量倾向于 2 倍;旧容量达到 256 后,会用一个公式平滑过渡到约 1.25 倍。还有一个经常被忽略的细节:公式算出来的只是目标容量,runtime 真正分配内存时还会受 allocator size class 影响,所以最终 cap 可能被向上取整。
素材里的扩容示例跑出来是这样:
| |
你会发现,它既不是一路 2 倍,也不是从某个点开始精确 1.25 倍。它在变缓。
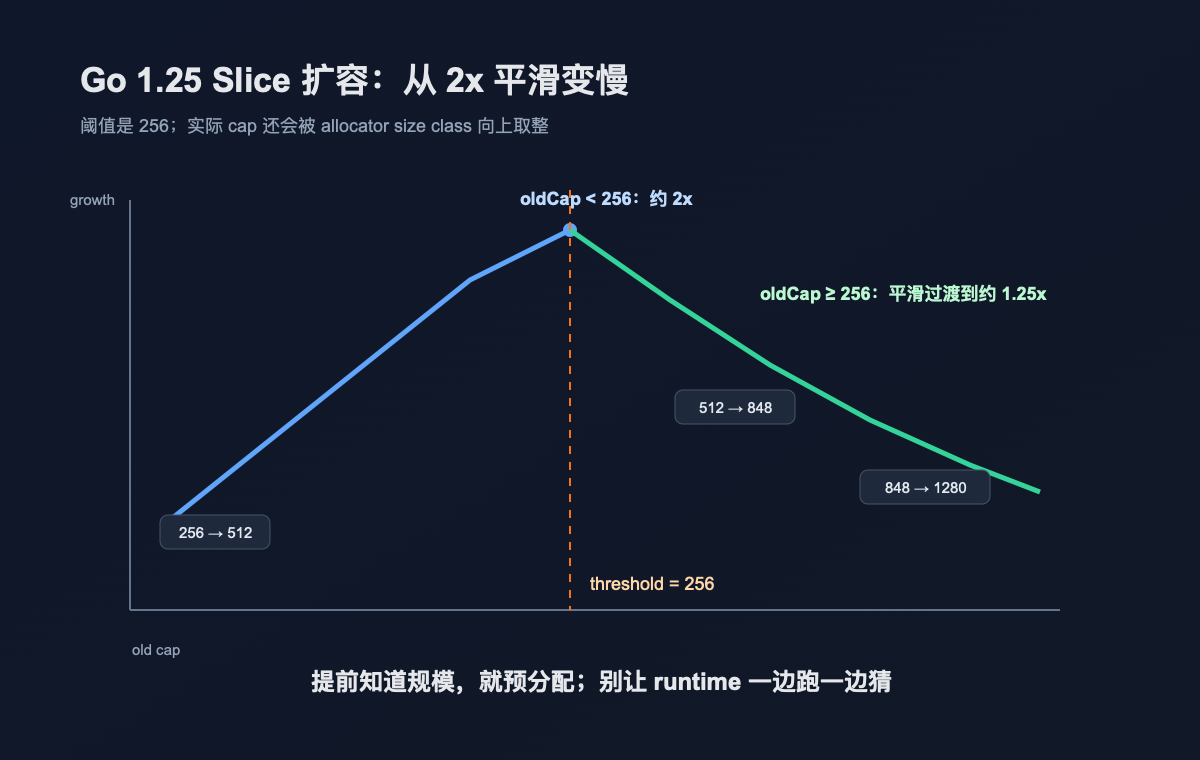
这个策略背后的取舍很直接:小 slice 扩容太频繁不划算,翻倍可以少搬几次;大 slice 如果还一直翻倍,内存浪费会很明显,所以增长要收着点。
这也是为什么写高吞吐代码时,make([]T, 0, n) 很有用。
本机 benchmark 里,对 10,000 个 int 做 append,不预分配时是 19 次分配,约 357 KB;预分配后降到 1 次分配,约 80 KB。耗时也从三万多 ns 降到九千多 ns。这个数字只代表 Apple M1 Pro + Go 1.25.4 + 当前 benchmark,不该当成普适常数,但趋势很清楚:你提前知道规模,就别让 runtime 一边跑一边猜。
slice 的坑,通常不是语法坑,是所有权坑
slice header 可以复制,底层数组却不会跟着复制。
这句话看着简单,真正写业务代码时很容易忘。
最常见的第一类坑,就是刚才说的子切片别名。你从一个大 slice 里切出一段,传给另一个函数。对方 append 了一下,如果 cap 还够,写的还是同一块数组。于是调用方的数据被悄悄改了。
处理办法不是“永远不要 append”,而是先想清楚所有权:
- 如果只是读,直接传 slice 没问题;
- 如果要改元素,明确这是共享修改;
- 如果要 append 且不希望影响原数据,限制 cap,或者先 copy;
- 如果跨 goroutine 传递,最好把所有权边界说清楚,不要靠默契。
第二类坑,是小 slice 留住大数组。
比如你读了一个 128MB 的 buffer,只想保留里面几十个字节:
| |
看起来你只返回了 32 字节。实际上,small 的 header 仍然指向那块 128MB 的 backing array。只要这个小 slice 还活着,GC 就不能释放整块数组。
素材里的示例输出很直观:
| |
解决办法也很朴素:只保留你真的需要的那一小段副本。
| |
或者用 make + copy。关键不是哪种写法更优雅,而是你要让新的 slice 指向一块新的小数组。
真正成熟的 slice 使用习惯,不是背扩容规则,而是养成一个问题:这段数据归谁?
nil slice 和 empty slice,不要混着讲
nil slice 和 empty slice 在多数循环、append、len 判断里差别不大:
| |
它们都可以 append。
但它们不是同一个语义。a == nil 为 true,b == nil 为 false。更麻烦的是 JSON、API 返回值、配置语义里,null 和 [] 经常不是一回事。
所以业务代码里不要偷懒说“空就行”。如果你想表达“没有设置”,nil slice 更自然;如果你想表达“设置了,但内容为空”,empty slice 更自然。尤其是对外 API,最好在团队里约定清楚。
底层机制本身不复杂,复杂的是人会把两种语义混着用。
为什么 Go 不直接只给你 slice
说到这里,最初那个问题就能回答了:Go 为什么既要数组,又要 slice?
因为它们解决的不是同一个问题。
数组负责确定性。它告诉编译器和机器:这里有一段固定长度、连续排列、类型明确的数据。它像一块钢板,尺寸写在类型上,拎起来就是整块。
slice 负责弹性。它不拥有“动态数组”这个魔法,它只是拿着指针、长度和容量去描述数组的一段。需要增长时,runtime 决定是继续在原地写,还是分配新数组再搬过去。
这套设计有一种很 Go 的味道:底层尽量朴素,上层给你够用的抽象;抽象不假装没有代价,代价也不强迫你天天面对。
数组太硬,所以日常集合直接用它会难受。
slice 很顺手,所以你容易忘了它背后还有一块数组。
大多数 slice 问题,就发生在这两句话之间。
写 slice 代码时,先过这几个问题
如果你只想拿走一份实用检查清单,不用背源码,记住下面几句就够了。
第一,传 slice 不是复制数据。函数拿到的是 header 副本,但元素仍然可能共享。
第二,改 s[i] 一定是在改 backing array。只要别的 slice 也指向这块数组,它就能看到变化。
第三,append 是否影响原数据,看 cap 和扩容。容量够,原地写;容量不够,换数组。
第四,从大数据里切小片长期保存时,考虑 copy。否则你可能只是想留 32 字节,却把 128MB 一起留住。
第五,已知规模时预分配。不是为了炫技,是为了少分配、少搬家、少让 runtime 猜。
最后,不要把 slice 简化成“引用类型”。
这个说法太省事,也太容易让人误判。更准确的说法是:slice header 是值,底层数组可以共享。
这句话才是理解 Go slice 的入口。