channel 还是 mutex?先回答这五个问题
Go 并发代码里,channel 和 mutex 不是谁更高级的问题。mutex 保护一块状态,channel 描述一段关系。下次纠结工具前,先用这五个问题判断问题形状。
上一篇说到一个很典型的场景:为了写得“更 Go”,有人把一个普通 cache 写成了小型 RPC。
锁确实没了。
但你多了 request、reply channel、owner goroutine、退出顺序、取消处理。读一个 map,本来是一眼能看懂的临界区,最后变成了一套本地协议。
很多人看完这类代码,第一反应还是那个老问题:那到底该用 channel,还是 mutex?
这个问题本身就有点偏。
真正要问的不是“哪个更 Go”,也不是“哪个更高级”。真正要问的是:你现在面对的,到底是哪一种问题。
mutex 保护状态。
channel 描述关系。
这句话很短,但够用。下面这五个问题,就是把它拆开,变成你下次写代码前可以直接拿走的判断流程。
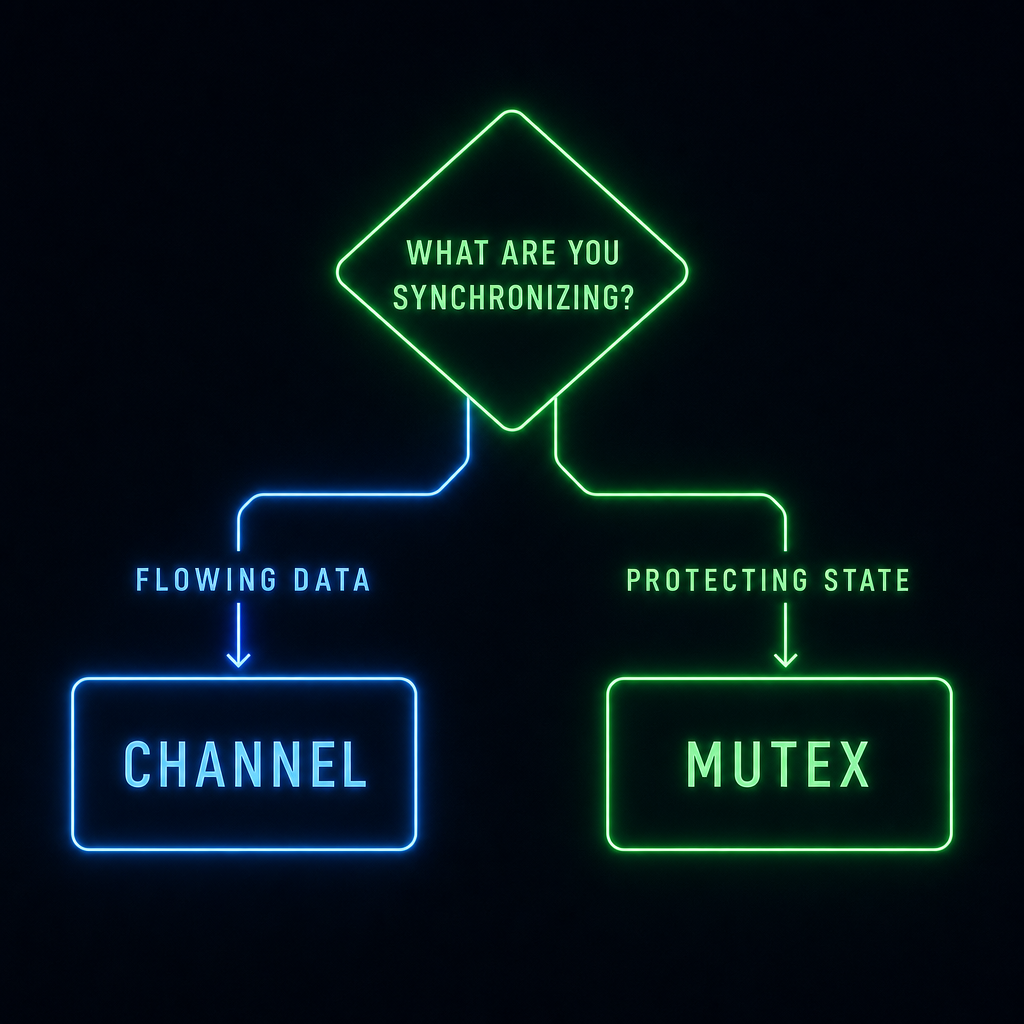
第一个问题:你是在传东西,还是在护东西?
先别看工具,先看问题形状。
如果你处理的是任务、事件、结果、错误、取消信号,它们本来就在 goroutine 之间移动,有明确的方向,有生产者和消费者,有交接关系,那 channel 往往更自然。
比如 worker pool:
| |
这里的 jobs 不是为了显得高级。它表达的是:任务从一个地方流向 worker;worker 处理完,再把结果交回 results。
读代码的人不用猜“谁负责拿任务”“谁处理完往哪里放”。关系就在代码表面。
但如果你处理的是 cache、map、计数器、连接表、配置快照、结构体内部不变量,问题通常不是“东西怎么流动”,而是“这块状态别被多个 goroutine 同时改坏”。
这时候 mutex 更直接:
| |
这段代码没有什么不 Go,也不丢人。
它的规则非常直:m 是共享状态,读写要进临界区。读的人一眼知道边界在哪里,不需要先理解一套额外协议。维护者也不用猜后台还有谁在替它兜底。
一把锁不可怕。
解释不清的协议才可怕。
第二个问题:数据有没有明确的拥有者?
“通过通信共享内存”这句话,最容易被念成口号。
很多人听成了:不要共享内存,能传 channel 就传 channel。
但 Go 从来不是一门禁止共享的语言。它有指针,有共享变量,有 sync.Mutex,也有 sync.RWMutex。真正关键的不是“有没有共享”,而是“同一时刻谁有权处理它”。
如果一份数据沿着流程移动,拿到它的人处理,处理完交给下一个阶段,中间最好不要被别人同时修改,那 channel 很合适。
例如一条 pipeline:上游生产数据,中间阶段加工,下游消费结果。数据在阶段之间交接,所有权跟着流动。你用 channel 写出来,读者能看见这条线。
但如果一份数据长期存在,很多地方都会读它、偶尔写它,它并没有真正“流”起来,只是被多个 goroutine 访问。那你强行用 channel 包一层,往往只是把共享状态藏到一个 goroutine 背后。
这不是不能做。
owner goroutine 模型在一些场景很有价值:比如状态变化必须严格按事件顺序发生,或者这块状态本来就是一个小状态机,外部应该通过消息驱动它。
问题是,普通 cache 通常不是状态机。
如果你为了读一个值,先发 getReq,再等 getResp,还要关心 owner goroutine 什么时候退出,这就要停一下了。你已经不只是在保护状态,你在设计协议。
协议一旦出现,就有生命周期。
谁发?谁收?谁关闭?调用方取消了怎么办?后台 goroutine 怎么退出?这些都不是附赠题,都是正文。
第三个问题:mutex 版本的规则会不会变复杂?
不要把这篇读成“能用锁就别用 channel”。
mutex 也会被滥用。
如果一个状态被多个锁共同保护,函数 A 拿锁 1 再拿锁 2,函数 B 拿锁 2 再拿锁 1;如果调用链跨了好几层,谁持锁、谁释放、谁不能阻塞,全靠注释和记忆维持;如果你改一行代码前要先在脑子里模拟锁顺序,那说明问题已经变味了。
这时 channel 可能反而能让结构变清楚。
一个常见做法,是把状态收拢到一个 owner goroutine。外部不直接改状态,只发送命令或事件。owner 按顺序处理消息,状态变化集中在一个地方。
这样做的好处不是“没有锁所以高级”。
好处是它把分散的共享写入,变成了集中的事件处理。很多隐含规则消失了:不再有多个地方同时改同一块状态,不再需要所有调用方理解锁顺序。
但这条路不是免费午餐。
你拿掉了锁,就要补上协议。你减少了共享写入,就要管理消息队列、取消、关闭、错误返回和退出顺序。
所以判断不是“channel 能不能替代 mutex”。判断是:哪一种复杂度更诚实。
锁规则已经复杂到解释不清时,考虑 channel。
channel 协议复杂到满屏 request、response、close、context 时,回头看看 mutex。
第四个问题:channel 版本是不是引入了更多生命周期?
很多 channel 方案看起来优雅,是因为它只展示了正常路径。
发送、接收、处理、返回。
一切顺利时,代码当然好看。
真实项目麻烦在后半段:下游不想要了怎么办?上游还在发怎么办?中间某个 worker 报错怎么办?谁来 close?close 早了会不会 panic?close 晚了会不会 goroutine 泄漏?
channel 一旦出现,你就不能只设计“怎么传”,还要设计“怎么停”。
比如很多人遇到 goroutine 卡住,第一反应是把:
| |
改成:
| |
短期看,阻塞少了。
但 buffer 不是取消机制。容量只是缓冲,不是收尾协议。它能吸收一段突发流量,也能表达一点背压,但它不回答这些问题:下游退出了吗?上游还会不会继续发?错误怎么传?谁负责关闭?
如果这些问题没有答案,buffer 再大也只是临时仓库。
尤其是 pipeline 和 worker pool,只要下游可能提前返回,上游的发送就可能永久阻塞。这个时候你需要的往往不是更大的 channel,而是 context、done channel、错误传播和明确的退出路径。
这也是 channel 的代价。
它让关系更清楚,但也逼你把关系的结尾写清楚。
第五个问题:读者接手时,能不能一眼看出边界?
工程代码最后不是写给语言社区投票的。
是写给下一个接手的人看的。
这句话很俗,但很管用。
很多并发代码的坏味道,不是某个语法写错了,而是维护者不知道该从哪里下手。看起来每个 goroutine 都有理由存在,每个 channel 都有名字,但整个系统谁等谁、谁能退出、谁还握着状态,没人能在一分钟内讲清楚。
如果别人打开代码,看到 mu.Lock(),马上知道下面是临界区;看到 defer mu.Unlock(),知道边界到哪里;看到 RLock 和 Lock,知道读写关系。这种朴素不是缺点。
反过来,如果别人看到一堆 channel,却要先搞懂:这个 goroutine 谁启动的?谁负责停?这个 reply channel 会不会没人收?这个 close 是谁触发的?context cancel 后请求会不会还卡着?那你最好确定,这套协议确实带来了结构收益。
channel 最好的使用场景,是它让关系更明显。
不是让代码看起来更“并发”。
比如任务分发、结果汇总、异步通知、阶段流水、取消广播,这些问题本身就有“谁把什么交给谁”的关系。channel 把这段关系写出来,读者会更轻松。
但普通状态保护不一样。
一个 map 放在那里,多处读写,需要保护。你用 mutex,问题和解法是贴在一起的。你用 channel,问题变成了“通过一个后台服务来访问 map”。这可能合理,也可能只是绕远。
判断标准很简单:
如果 channel 让边界更清楚,用它。
如果 channel 让读者先学一套私有协议,停一下。
一张可以直接拿走的判断表
下次再纠结 channel 还是 mutex,可以按这五个问题过一遍:
| 问题 | 更偏 channel | 更偏 mutex |
|---|---|---|
| 你是在传东西,还是护东西? | 任务、事件、结果、信号在流动 | map、cache、计数器、配置需要保护 |
| 数据有没有明确拥有者? | 数据沿流程交接,同一刻最好只有一个处理者 | 数据长期存在,多处读写 |
| mutex 规则是否复杂? | 多锁、锁顺序、跨函数持锁难解释 | 临界区短,边界清楚 |
| channel 协议是否复杂? | 发送、接收、关闭、取消都能说清 | 为简单访问引入 request/reply/owner 生命周期 |
| 接手者能否一眼看懂? | 关系浮到代码表面 | 状态保护直接可见 |
这张表不是标准答案。
它只是逼你别先选工具,而是先描述问题。
很多争论到这里就结束了:你会发现自己纠结的不是 channel 和 mutex,而是不知道这段代码到底想表达什么。
还有两个边界,也值得顺手记住。
第一,简单不等于粗糙。sync.Mutex 看起来没有 channel 漂亮,但它如果能把共享状态的边界压得很短、很清楚,就是好设计。工程里最危险的不是朴素,而是为了显得高级,把每个读写都绕成一次消息往返。
第二,结构化不等于 channel 化。channel 能让流程关系浮出来,但前提是你的问题真的有流程。没有生产者、消费者、阶段、取消、回收这些关系,硬塞一个 channel,只会让读者先背你的私有通信协议。
所以这五个问题最后指向的不是“选 A 还是选 B”。
它指向的是一个更基础的动作:先把问题说准。
三种常见误用,基本都卡在这五个问题上
第一种,是用 channel 包简单状态。
计数器、普通 cache、共享 map,本来一把锁就能说清楚。你非要启动一个 goroutine,让所有读写都发消息进去,代码看起来更 Go,问题却没更清楚。
第二种,是用 channel 逃避所有权设计。
把指针塞进 channel,不等于自动安全。如果传过去以后,原 goroutine 还继续改,接收方也在改,data race 照样会发生。真正重要的是访问权,不是运输方式。
第三种,是把 buffer 当成止痛片。
卡住了就加容量,泄漏了就加容量,偶发阻塞也加容量。容量能缓冲压力,但不能替你设计退出。该有的取消、关闭、错误传播,一个都少不了。
这三种误用背后,其实都是同一个问题:只看见了 channel 这个工具,没看见它要求你承担的协议。
别把工具当信仰
Go Wiki 里那句建议很朴素:用最能表达问题、也最简单的那个。
这比很多“Go 风格”争论都可靠。
channel 不是高级锁。
mutex 也不是低级 Go。
真正好的 Go 并发代码,不是看起来用了多少 channel,而是别人接手时能不能看出来:谁在工作,谁在等待,谁拥有数据,谁负责结束。
判断工具前,先判断问题。
如果你是在传任务、传结果、传信号、交接访问权,让 channel 把这段关系写出来。
如果你只是在保护一块共享状态,老老实实用 mutex。
朴素一点没关系。
可解释,比有姿势重要。
这一篇解决的是“怎么选”。下一篇再往下走:当你真的决定用 channel,select、close 和生命周期才是最容易翻车的地方。很多 goroutine 泄漏、偶发卡死、线上假死,不是因为你不会发送和接收,而是因为你没把通信协议收尾。
如果你觉得这套判断有用,可以先关注。下一篇我们专门拆:select 怎么等,close 谁来关,生命周期怎么不烂尾。