Go 服务 goroutine 涨了,别先猜:按这条流程查 context 泄漏
从 goroutine 数上涨开始,按采样、pprof 定位、go vet 静态检查、创建/取消/响应三条线分析、修复验证的顺序,给出一套排查 Go context 相关泄漏的最小实操流程。
线上 goroutine 数开始往上爬,最怕的不是它涨。
最怕的是你盯着监控看了十分钟,然后开始猜:是不是 context 泄漏了?是不是超时没生效?是不是某个 channel 卡住了?
这些猜法都有可能对,也都有可能错。
runtime.NumGoroutine() 只能告诉你“现在有多少 goroutine”。它不会告诉你这些 goroutine 停在哪里,也不会告诉你是谁创建的,更不会告诉你为什么没有退出。
排查这类问题,第一步不是解释 context 原理。
第一步是采样。

这篇是 Go context 系列第三篇。前两篇讲过 context 的生命周期、cancel 的边界,以及 Go 为什么坚持显式传 ctx。
这一篇换一个角度:不从源码开始,从排查现场开始。
一套最小流程就够了:
| |
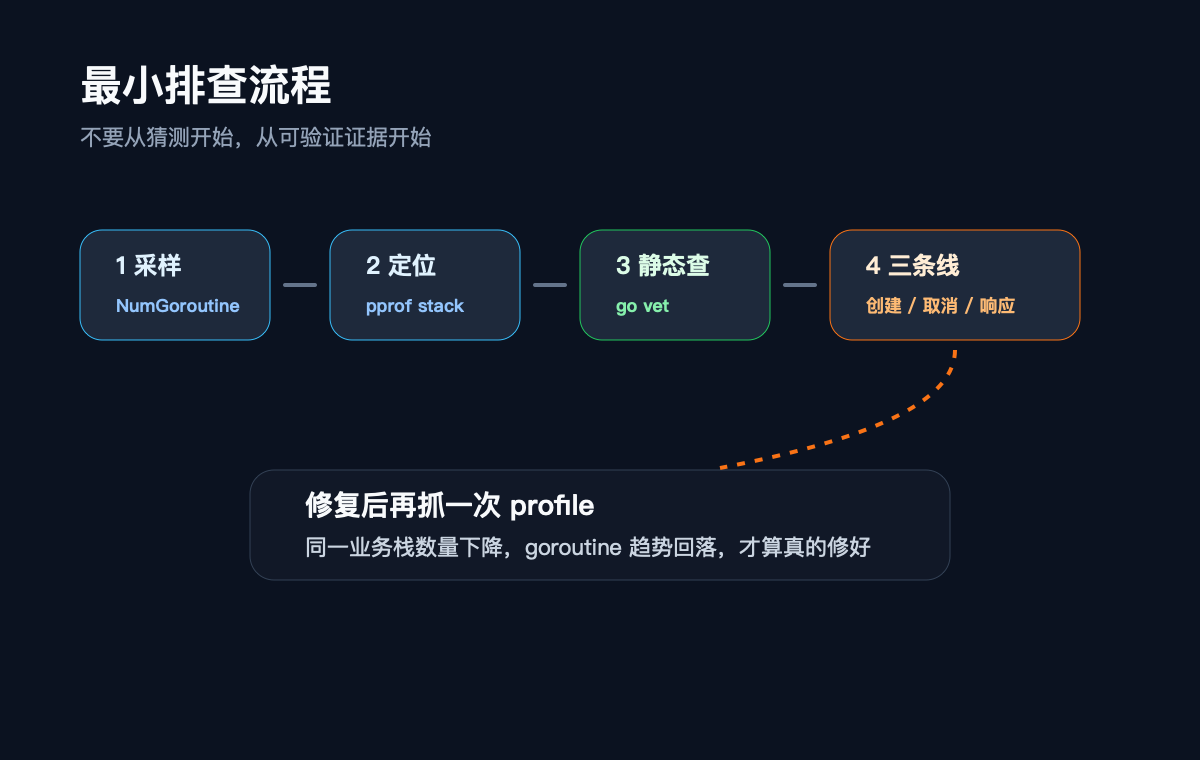
goroutine 泄漏不是靠感觉排查的,是靠流程逼近的。
第一步:先确认“在涨”,不要急着定性
你可以先在服务里做一个最小采样。
| |
这段代码解决的不是“定位根因”,而是确认趋势。
如果 goroutine 数只是请求高峰时上去,低峰时能回来,未必是泄漏。它可能只是并发量变化。如果 goroutine 数持续上涨,压测停了也不回落,才值得进入下一步。
这里要压住一个误判:
goroutine 数一涨,不等于 context 泄漏。
它也可能是 channel 没人读、锁竞争、网络读写卡住、后台任务堆积、连接池配置不合理。context 相关问题只是其中一类。
所以 NumGoroutine() 只负责把你送到门口。真正进门,要靠 pprof。
第二步:接入 pprof,把“数量”变成“栈”
最小接入方式是引入 net/http/pprof,单独起一个只监听本地地址的调试端口。
| |
生产环境不要裸奔暴露到公网。更稳的做法是只绑定内网或本机地址,再通过跳板机、端口转发、临时安全组规则访问。
有了 pprof,先抓 goroutine profile。
| |
这两个命令的区别很实用:
debug=1:看聚合后的栈摘要,适合快速判断哪一类 goroutine 数量最多;debug=2:看完整 goroutine 栈,包含等待状态,适合确认它到底卡在 channel、IO、select 还是锁上。
官方 runtime/pprof 文档里也写得很清楚:debug=1 会输出带函数名和行号的可读文本;对 goroutine profile 来说,debug=2 会用类似 panic 时打印 goroutine stack 的形式输出完整栈。
也就是说,debug=1 帮你看“哪一堆最多”,debug=2 帮你看“这一堆具体死在哪”。
看一个最小例子。
| |
这段代码的问题不在 cancel() 没调用。它调用了。
问题在 worker 根本没有接收 ctx,也没有监听 ctx.Done()。上游把“该停了”这句话送出去了,worker 在另一个房间里,门都没开。
抓 debug=1,你会看到类似输出:
| |
这已经足够给出第一条线索:24 个 goroutine 里,有 20 个都停在 main.worker。
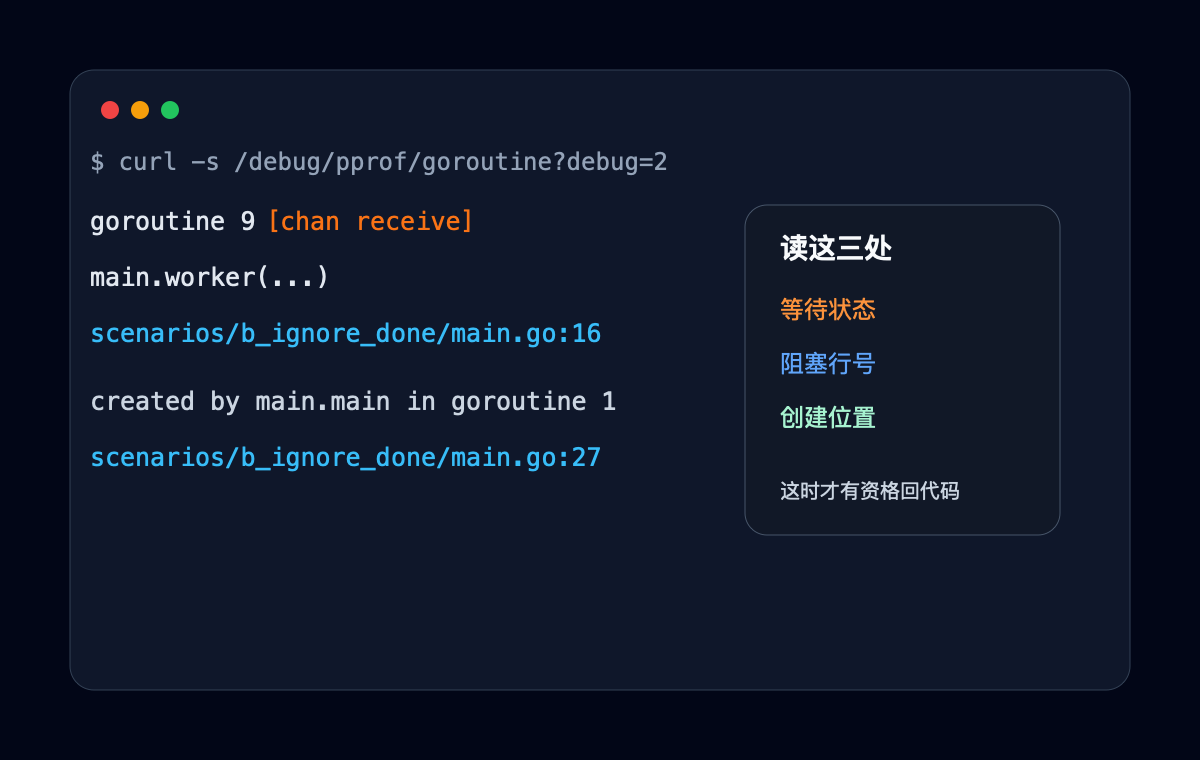
再看 debug=2:
| |
这里有三个关键信息:
- 等待状态是
[chan receive]; - 阻塞位置是
main.worker第 16 行; - 创建位置是
main.main第 27 行。
这比“goroutine 涨了”有用太多。
你现在不是在猜 context,你已经拿到了等待点和创建点。
第三步:用 go tool pprof 看占比,不要只靠肉眼翻栈
当 goroutine 不多时,debug=2 直接看就够了。
但线上 profile 可能很长。几百个、几千个 goroutine 混在一起,肉眼翻文本容易漏掉主线。这时可以让 go tool pprof 帮你聚合。
| |
进入交互模式后,常用三个命令:
| |
也可以直接看 top:
| |
示例输出里有一行很醒目:
| |
不要被 runtime.gopark 吓到。它只是 Go runtime 把 goroutine 停起来的底层位置。
真正该看的,是业务函数和等待类型。
这里的主线是:main.worker 占了 20 个 goroutine,底层都落到 runtime.chanrecv。换成人话就是:一批 worker 卡在 channel receive 上。
接下来就该回代码了。
第四步:先跑 go vet,抓住能静态抓住的问题
pprof 是现场采样,go vet 是静态闸门。
它们不是一类工具,不要混着期待。
go vet 对 context 最有用的一点,是能检查 CancelFunc 是否被丢弃,尤其是 WithCancel、WithTimeout、WithDeadline 返回的 cancel 没有在所有控制流路径上使用。
比如这段:
| |
跑:
| |
输出会直接指出问题:
| |
Go 官方 context 文档也明确写了:调用 CancelFunc 会取消 child 和它的 children、移除 parent 对 child 的引用,并停止关联 timer;不调用 CancelFunc 会让 child 和 children 一直保留到 parent 被取消;go vet 会检查 CancelFunc 是否在所有控制流路径上使用。
所以这条建议很硬:
| |
尤其是函数提前 return、循环里创建 timeout context、错误路径分支很多时,go vet 比肉眼 review 靠谱。
但边界也必须说清楚。
go vet 是闸门,不是侦探。
它能抓“你把 cancel 丢了”。它抓不住“你的 goroutine 收到了 ctx 却不监听 Done”。它也不会替你判断业务 goroutine 为什么卡在 channel 上。
所以 go vet 通过,不代表没有 context 相关泄漏。
它只说明某一类静态错误暂时没被发现。
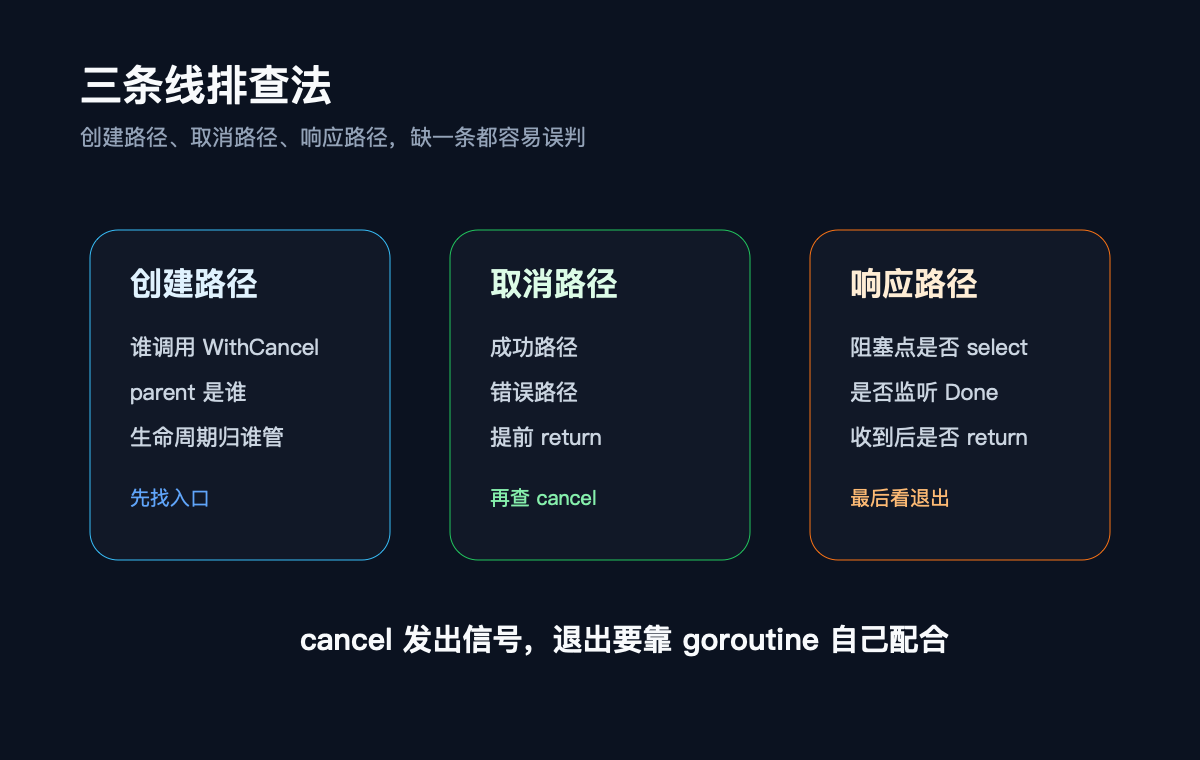
第五步:用“三条线”回到代码
拿到 pprof 和 vet 结果后,不要立刻改。
先按三条线把问题捋清楚:
- 创建路径:谁创建了
ctx?谁调用了WithCancel/WithTimeout/WithDeadline? - 取消路径:返回的
cancel有没有在成功、失败、提前返回路径上被调用? - 响应路径:所有可能阻塞的 goroutine 有没有监听
ctx.Done()?监听后有没有真的退出?
三条线缺一条,结论就可能跑偏。
线一:创建路径
先找到创建 context 的地方。
| |
要问两个问题:
- 这个 context 的生命周期属于谁?
- 它的 parent 是请求级、任务级,还是进程级?
很多泄漏不是因为 context 本身复杂,而是生命周期一开始就混了。
比如把请求级 context 派生出来后塞进全局任务队列,或者把长生命周期 background context 又套了很多 value 和 cancel child。时间一长,代码看起来都在传 ctx,实际谁该负责结束它,没人说得清。
线二:取消路径
再找 cancel 有没有跑到。
最常见的修复是创建后立刻 defer cancel():
| |
如果是在循环里,不能无脑 defer 到函数退出,因为循环很多时会把释放拖到最后。可以包一层函数,让 defer 的作用域变小。
| |
也可以显式调用:
| |
重点不是一定要用哪种写法。
重点是所有路径都要能走到 cancel()。
线三:响应路径
最后看阻塞点有没有听 ctx.Done()。
前面的错误代码是这样:
| |
修复后应该把 context 带进来:
| |
调用侧也要把同一个生命周期传进去:
| |
cancel() 不是强杀按钮,它只是把“该停了”这句话送出去。
真正退出,要靠 goroutine 自己在可能阻塞的位置监听这句话。
这也是排查 context 相关 goroutine 泄漏时最该盯的地方:不是代码里有没有 ctx,而是阻塞点有没有把 ctx.Done() 放进 select。
两种最值得重点排查的场景
上面是流程。下面把两个最常见的场景拆开。
不是为了背模式,而是为了你在 pprof 里看到类似栈时,知道下一步该查什么。
场景一:WithTimeout 的 cancel 被丢弃
错误代码:
| |
表现通常不是 goroutine 立刻暴涨。
更常见的是 timer、child context、parent 对 child 的引用被多留了一段时间,直到 deadline 到或 parent 被取消。请求量一大,这类“多留一会儿”的资源就会堆起来。
排查工具优先级:
- 先跑
go vet ./...; - 如果报 lostcancel,先修掉;
- 再看 goroutine 和 heap profile 是否回落。
修复:
| |
如果是在循环里,按前面说的缩小 defer 作用域。
这里不要写成“忘记 cancel 一定会泄漏 goroutine”。这句话不准。
更准确的是:忘记 cancel 会让 context 相关资源保留得更久;是否表现为 goroutine 泄漏,要看有没有 goroutine 在等这条取消信号,以及业务代码有没有其他阻塞点。
场景二:goroutine 不监听 ctx.Done()
错误代码:
| |
表现很直接:goroutine 数持续上涨,pprof 里看到一批 goroutine 卡在同一个业务函数上。
debug=1 看到聚合:
| |
debug=2 看到等待状态:
| |
go tool pprof -top 看到占比:
| |
这时三条线里的重点是响应路径。
不是问“cancel 有没有调”,而是问:main.worker 有没有办法收到取消信号?收到以后有没有 return?
修复通常是把阻塞操作包进 select:
| |
如果你的 worker 是循环,还要注意 break 和 return 的区别。
| |
不要只 break 掉 select,结果外层 for 继续跑。
这种 bug 很隐蔽,review 时也很容易漏。
WithValue + 大对象:要看 heap,不要只看 goroutine
还有一类问题,goroutine profile 不一定最显眼,heap profile 更有用。
比如有人把大对象塞进 context:
| |
如果这个 context 生命周期被拉长,大对象会跟着 value 链一起被保留。再叠加 goroutine 等待 ctx.Done(),就是双重问题:goroutine 不退,heap 也下不来。
这时要抓 heap:
| |
这类问题的修复方向不是“别用 WithValue”。
Go 官方文档说得更窄:Context values 应该只用于跨 API 和进程边界的 request-scoped data,不要拿来传函数可选参数。放 request id、trace id 这类小型元数据通常没问题;放大对象、缓存、数据库连接、请求完整 dump,就很容易把生命周期拖乱。
所以排查时要多问一句:
这个值是不是必须跟着 context 走?
如果不是,把它从 context 里拿出来,显式作为参数传,或者放到更清楚的生命周期对象里。

Go 的很多设计都在逼你把边界说清楚。context 也是这样。它不是一个方便你什么都塞的袋子,而是一份生命周期契约。
修完以后,必须验证回落
改完代码以后,不要只看测试过没过。
泄漏类问题要看趋势回落。
最小验证可以这样做:
| |
然后看三件事:
runtime.NumGoroutine()是否在压力结束后回落;debug=1里同一业务栈的数量是否下降;debug=2里是否还存在同一批等待状态。
如果涉及 WithValue 或 context 链保留,还要补 heap profile:
| |
注意,heap profile 受 GC 和采样影响,不要拿单次数字做绝对判断。更稳的是对比同一复现场景下修复前后是否明显回落。
把这套流程放进日常工程里
最后给一个可落地清单。
第一,把 go vet 放进 CI。
| |
它不万能,但 lostcancel 这种问题不该靠上线后 pprof 才发现。
第二,给服务保留受控的 pprof 入口。
| |
调试端口不要暴露公网。内部服务可以配合内网访问、认证代理、端口转发或临时开关。
第三,给 goroutine 数做周期采样。
| |
如果接入 Prometheus,就把它变成指标。不要等到服务已经抖了,才第一次想起看 goroutine。
第四,review 代码时盯三条线。
| |
这张检查表比“记住 context 原理”更有用。
因为线上事故不会按源码章节发生。它只会给你一个现象:goroutine 涨了,延迟抖了,接口开始超时。
这时你需要的不是更多概念,而是一条能走下去的路。
先采样,不要猜。
找到等待点,再回代码。
按创建、取消、响应三条线查。
最后用趋势回落证明自己真的修好了。