超时到了,goroutine 还在涨:context 到底背不背这个锅?
线上接口超时后 goroutine 数还在上涨,很多人第一反应是 context 没生效。真正的问题往往不是 timeout 没到,而是业务 goroutine 没有响应取消信号。
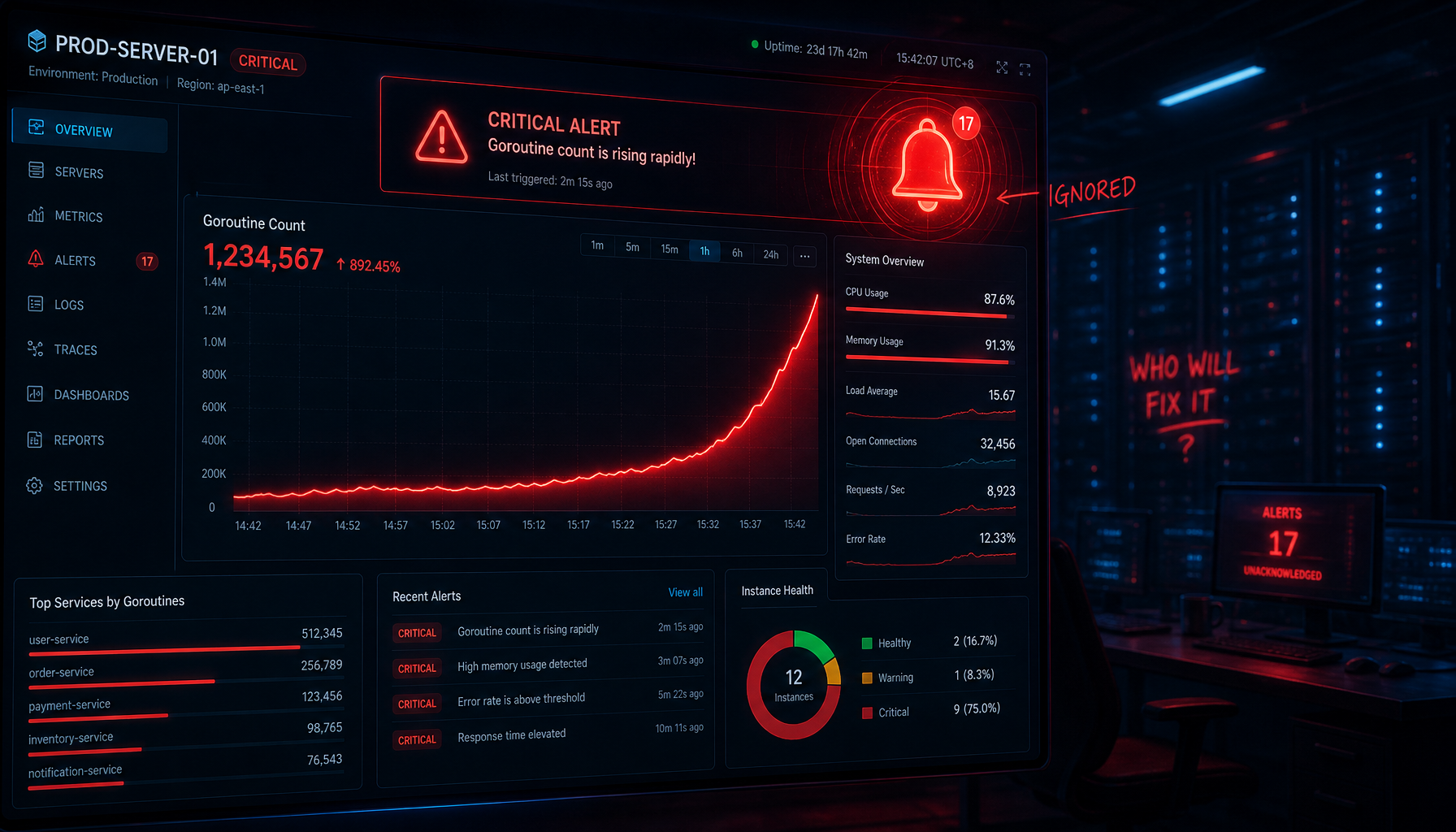
接口超时了,goroutine 曲线还在往上爬。
日志里已经打出 context deadline exceeded,调用方也早就不等了。你盯着监控看了十分钟,心里开始冒出那个判断:是不是 context.WithTimeout 没生效?
大多数时候,不是。
timeout 可能已经生效了。只是你的 goroutine 没听见,或者听见了也没有退出。
这就是 Go context 最容易被误会的地方:很多人把它当成清洁工,以为只要传下去、超时一到,它就会替你把现场收拾干净。
但 context 没有这么大的权力。
它不会杀 goroutine,不会强制打断你的业务逻辑,不会替你关闭 channel,也不会把一个卡住的 worker 从阻塞点里拽出来。
它只负责把一句话传下去:该停了。
听不听,是你的代码的事。
context 不是清洁工,是通知协议
先把这个判断钉牢:
context 不是清洁工,它只是通知协议。
这句话听起来简单,但很多线上问题正是卡在这里。
你创建了一个带超时的 context:
| |
这段代码表达的是:这条调用链最多等 200 毫秒,时间到了就发出取消信号;函数提前结束时,也把相关资源释放掉。
注意,是“发出取消信号”,不是“停止所有工作”。
如果下游代码根本不看这个信号,它就会继续跑。比如这样的 worker:
| |
你把 ctx 传进来了,但它没有用。timeout 到了,ctx.Done() 会被关闭,ctx.Err() 会变成 context deadline exceeded。可这个 goroutine 仍然卡在 <-ch,它根本没有机会知道外面已经不等了。
于是你看到的现象就很诡异:调用方已经超时,错误也返回了,但 goroutine 数还在涨。
这不是 context 失灵。
这是协议发出去了,现场没人执行。
真实排查里,这个误判很常见。监控平台上只会告诉你“goroutine 数变多了”,日志里只会告诉你“deadline exceeded”。这两个信号叠在一起,太容易让人产生一种错觉:既然 deadline 已经 exceeded,goroutine 就应该少下来;现在没少,说明 context 出问题了。
可 goroutine 不会因为某个错误字符串自动消失。
一个 goroutine 能不能退出,取决于它当前停在哪里。如果它停在一个没有结果的 channel 接收上,停在一个没有超时控制的外部调用上,或者停在一个自己写的无限循环里,context 只能站在旁边提醒。提醒到了,代码没有接,现场还是会继续堆。
所以排查时不要只盯着“有没有传 ctx”。这只能证明你把通知单递出去了,不能证明收件人看了。
timeout 负责到点敲门,不负责把人拖出来。
Go 选择的是协作式取消。所谓协作,就是标准库只提供信号,业务代码自己决定在哪里响应、怎么退出、退出前释放什么。
这也是为什么 context 很克制。它没有设计成“强制中断线程”的工具,因为强制中断看起来省事,实际会把资源状态、锁状态、连接状态全部弄乱。Go 更愿意让退出路径显式地写在代码里。
麻烦一点,但更可控。
把 Context 接口看薄一点
很多人一提 context,就开始背 WithCancel、WithTimeout、WithDeadline、WithValue。
先别急。
context.Context 接口本身只有四个方法:
| |
把它看薄,反而更容易理解。
Deadline 说的是:这条调用链最晚什么时候结束。
Done 说的是:取消信号从哪里来。
Err 说的是:为什么结束,是主动取消,还是 deadline 到了。
Value 说的是:少量请求级元数据怎么沿着调用链传下去。
四件事合起来,context 表达的是一条调用链的生命周期,而不是一个万能参数包。
所以它的正确位置通常在函数的第一个参数:
| |
这不是形式主义。
它在提醒调用方和被调用方:这个函数不是孤立运行的。它属于某条请求链路,可能被取消,可能有 deadline,也可能带着 request id、trace id 这类小型元数据。
但真正的业务参数,不该藏进 Value 里。
如果你把 logger、DB handle、大对象、可选参数都塞进 context,代码短期会变顺手,长期会变浑。后来的人看函数签名,已经看不出这个函数真正依赖什么。
context 最好的用法,不是让函数签名变短,而是让生命周期变清楚。
cancel 到底做了什么
理解了“通知协议”,再看 cancelCtx 就没那么玄了。
WithCancel、WithTimeout、WithDeadline 创建出来的 context,背后都绕不开一棵取消树。
父节点取消,会向下通知所有子节点;子节点取消,通常不会反过来取消父节点。
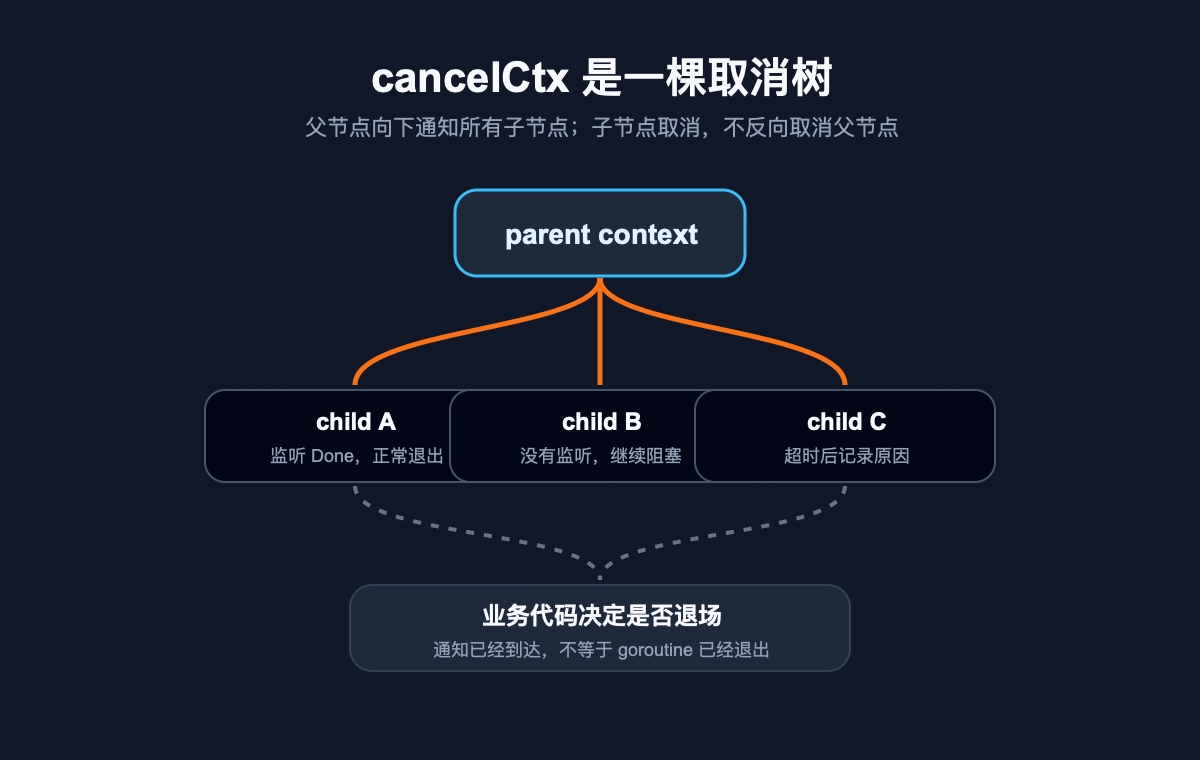
一个请求进来,最外层 context 是根。你给数据库查询派生一个子 context,给远程 RPC 派生一个子 context,给异步任务再派生一个子 context。这些节点挂在同一棵树上。
父节点一取消,通知就往下传。
但这里仍然要记住边界:传下去的是“取消信号”,不是“强制退出”。
cancelCtx 里最关键的东西,可以粗略理解成三类:
| |
真实源码里还有锁和细节,这里先不展开。先抓住这三件事就够了。
第一,done 是取消信号。有人调用 Done() 时,拿到的就是这个 channel。取消发生时,标准库会关闭它。
第二,children 保存子 context。父节点取消时,会遍历这些子节点,把取消继续传下去。
第三,err 和 cause 记录取消原因。普通取消是 context.Canceled,超时是 context.DeadlineExceeded。
所以 cancel 真正做的事并不神秘:记录原因,关闭 done,通知子节点,必要时把自己从父节点的 children 里摘掉。
它没有杀 goroutine。
它只是把门铃按响了。
cancel 不是杀 goroutine,而是关掉一扇门铃。
门铃响了以后,屋里的人要不要出来,要看你的代码有没有写这条路。
正确代码里,Done 必须被听见
一个能响应取消的下游调用,通常长这样:
| |
这段代码的重点不在 select 本身,而在它把“业务结果”和“取消信号”放在了同一个等待点里。
谁先到,就处理谁。
结果先回来,就返回结果。取消先到,就返回 ctx.Err()。
这才叫协作式退出。
很多 goroutine 泄漏问题,恰好就少了这个等待点。代码把 ctx 一路传下去,看起来很规范,但真正阻塞的地方没有监听 Done:
| |
jobs 一直没数据时,这个 goroutine 会一直等。上游取消了,它也不知道。
更稳的写法是把退出路径写出来:
| |
这段代码不花哨,但它把一个关键问题回答清楚了:上游不等的时候,我怎么退。
这里最容易漏掉两类地方。
第一类是循环。很多 worker 写成 for { ... },里面只处理业务消息,没有退出分支。流量正常时它看不出问题,一旦上游取消、队列不再投递、某个分支提前返回,它就会留在那儿等下一次永远不会来的事件。
第二类是“看起来已经传了 ctx”的封装。外层函数签名有 ctx context.Context,调用链也一路往下传,但真正阻塞的那一层没有用它:可能是自己封装的重试循环,可能是一个没有 deadline 的第三方调用,也可能是一个只收结果、不收取消信号的内部 channel。
这种代码最骗 review。你扫一眼,看见 ctx 在函数间传来传去,会以为生命周期已经设计好了。真正出事时才发现,ctx 只是路过了现场,没有进入事故发生的房间。
所以不要问“代码里有没有 ctx”。要问“阻塞点有没有和 ctx.Done 放在同一个 select 里”。
这两个问题差别很大。
真正可靠的 Go 服务,不是“到处都传了 ctx”,而是每个可能阻塞的地方,都知道怎么听见 Done。
子取消不影响父,是边界感
取消树还有一个很重要的方向感:父能通知子,子通常不反向取消父。
这不是随便设计的。
想象一个请求里有三个子任务:查缓存、查数据库、查远程服务。远程服务那条子链超时了,不代表整个请求的父 context 一定要被取消。父级是否放弃,要由父级的业务逻辑决定。
如果子节点能随便取消父节点,调用链就会变得很危险:一个局部失败,可能把整条链路都掀翻。
所以 context 的取消传播默认是向下的。
父节点说“这批活都不用干了”,子节点应该收。
子节点说“我这边不干了”,父节点不应该自动崩。
这背后其实是 Go 很典型的设计气质:控制权要清楚,生命周期要显式,边界不要越级。
这也是为什么你排查问题时,不能只看某个子函数里有没有 cancel。你要沿着调用链问:谁创建了 context?谁负责释放?谁有权决定整条链路结束?
这些问题不回答,ctx 传得再勤也只是表面规范。
线上看到 goroutine 涨,先问三件事
回到开头那个现场。
接口超时了,goroutine 还在涨。别急着说“context 泄漏了”。这个判断太快,通常也太粗。
先问三件事。
第一,cancel 调了吗?
创建 WithCancel、WithTimeout、WithDeadline 后,返回的 CancelFunc 必须有明确去处。最常见的写法是创建后立刻:
| |
如果不能 defer,比如在循环或异步启动里,也要确保成功路径、错误路径、提前返回路径都会释放。
这里的关键不是背一条“必须 defer”的规矩,而是要知道谁负责收尾。函数级的短生命周期,defer cancel() 通常最稳;循环里每次派生子 context,就不能把所有 cancel 都堆到外层函数结束才执行,否则每一轮的 timer、父子引用都会被拖得更久。异步任务里更要明确:任务完成、任务失败、上游放弃,分别由谁调用 cancel。
第二,Done 听了吗?
所有可能长时间等待 channel、队列、网络、锁、外部任务的地方,都要问一句:上游不等了,我怎么知道?
如果答案是“不知道”,那 goroutine 涨就不奇怪。
第三,退出路径走得到吗?
有些代码表面监听了 ctx.Done(),但真正耗时的工作在另一个不可中断的调用里,或者进入了没有 select 的内部循环。这样的代码也会让取消信号变成摆设。
还有一个细节:不要把 ctx.Err() 当成排查终点。
context deadline exceeded 只能说明这条调用链因为超时结束了,它不能告诉你哪个 goroutine 没退,也不能告诉你哪个 channel 没关。它更像事故现场的一张标签:这里发生过超时。真正的定位,还要回到 goroutine profile、调用栈和业务等待点。
如果你在日志里只记录 ctx.Err(),排查时会很被动。更好的做法是把关键等待点的身份写清楚:哪个 worker、哪个队列、哪个下游调用、哪个请求阶段。这样下一次看到 goroutine 上涨时,你不是在一堆 deadline exceeded 里猜,而是能沿着等待点往回找。
这三问比“context 有没有泄漏”更有用。
因为它们把问题从一个抽象黑锅,拆回了具体代码路径。
cancel 调了吗?
Done 听了吗?
退出路径走得到吗?
下次线上再看到 goroutine 曲线往上爬,先别急着怪 context。
它能做的,可能已经做完了。
真正没做完的,是你的收尾协议。把这条边界想清楚,context 反而会变得更好用:它不替你兜底,但它会逼你把谁负责退出、谁负责释放、谁负责停止等待写清楚。
下篇继续往下拆:WithTimeout 后面那句 defer cancel() 到底释放了什么,为什么“超时会自动发生”不等于“你可以不 cancel”。如果你也在维护 Go 服务,关注后续这一篇,很多线上 timeout 和资源保留问题,都会在那一句代码里露出尾巴。