Go 服务被 OOMKilled,别先怪 GC
从一次 Kubernetes 里的 OOMKilled 讲起,整理 Go GC 线上排查顺序:heap profile、diff_base、MemStats、RSS、GOMEMLIMIT、K8s limit 与监控告警。
服务又被 OOMKilled 了。
Pod 刚重启,群里已经有人开始翻 GC 日志。有人说 GC CPU 到了 20%,有人说把 GOGC 调低一点,还有人建议直接上 GOMEMLIMIT。
这些动作不一定错,但顺序错了。
OOMKilled 是结果,不是根因。它只说明容器被内核杀掉了,不说明是谁把内存吃掉了。可能是 Go heap 真的在涨,可能是 goroutine 泄漏把栈和引用一起拖大,可能是 alloc_space 很高导致 GC 忙,可能是 RSS 里有 cgo、mmap、tmpfs,也可能只是容器 limit 给得太紧。
Go 服务的内存问题,最怕一句话定性。
一旦你把所有问题都叫“GC 问题”,排查就会变成调参赌博:今天调 GOGC,明天加 limit,后天又开始怀疑 pprof 没抓准。真正稳定的做法,是先把几条线拆开:Go 堆、Go runtime 管理的内存、RSS、容器 limit,以及业务生命周期。
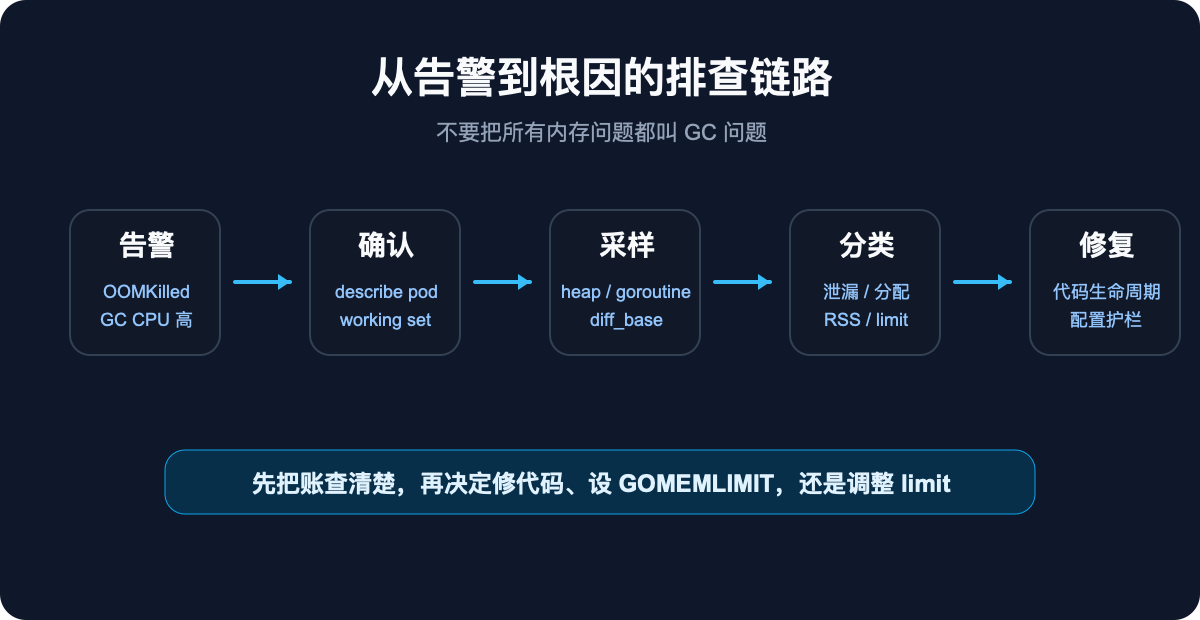
第一步不是调参数,是确认谁杀了你
线上看到内存上涨,第一件事不是打开 pprof,也不是改 GOGC。
先确认事故事实。
| |
你要先回答几个问题:
| |
这一步很土,但很重要。因为应用日志经常来不及写完,Pod 已经被杀了。kubectl describe pod 里的 Last State、Reason、Exit Code、Events,才是第一现场。
很多排查一开始就跑偏,是因为大家默认“进程内存高 = Go heap 高”。这个等号不成立。
Go heap 是 runtime 看到的堆。RSS 是操作系统看到的进程驻留内存。容器 working set 是 cgroup 看到的容器内存。它们有关联,但不是一回事。
heap profile 解释 Go 对象,RSS 解释操作系统账本。两者不能互相替代。
第二步:抓两次 profile,不要迷信一次 top
如果服务还活着,先抓证据。
生产环境不要把 pprof 裸露在公网。更稳的做法是只监听 localhost,或者用内网、鉴权 sidecar、临时端口转发暴露。
服务里最小开启方式类似这样:
| |
现场采样:
| |
等一个业务周期,或者等问题继续扩大,再抓第二次:
| |
然后看差异:
| |
-diff_base 的价值在这里:它不是告诉你“谁最大”,而是告诉你“谁在变大”。
泄漏排查靠趋势,不靠截图。
单次 top 很容易误导。一个函数排第一,可能只是它负责分配大块临时 buffer;这些对象未必还活着,也未必是泄漏。真正值得盯的是:同一类对象在两个时间点之间持续正增长,并且业务回落后不回落。
inuse_space、alloc_space、inuse_objects 不要混着用
pprof 里最常用的几个视角,回答的是不同问题。
| |
inuse_space 高,说明现在还有对象占着堆。它适合看无界缓存、全局 map、请求对象被错误持有。
alloc_space 高,只说明历史分配多。它更适合查“为什么 GC 老是跑”,不适合直接断言泄漏。
inuse_objects 看的是数量。很多小对象单个不大,但数量爆炸,一样会让 GC 扫描成本上去。比如 map entry、短小结构体、闭包、channel 上堆积的消息。
这三种视角混在一起,就会出现很常见的误判:看到 alloc_space 第一名,就说它泄漏;看到 heap 不高,就说不是内存问题;看到 RSS 高,就说 Go 没回收。
都太快了。
更稳的判断顺序是:
| |
RSS 比 heap 大,不代表 Go GC 坏了
容器里最容易吵起来的地方,是 RSS 和 heap 对不上。
你在 pprof 里看到 live heap 只有 430MiB,监控里 container working set 已经 920MiB。第一反应可能是:Go GC 没把内存还回去。
有可能,但不能这么下结论。
Go runtime 里有几组字段值得一起看:
| |
几个字段先记住含义:
| |
如果 HeapIdle - HeapReleased 很大,通常说明最近有过内存尖峰,runtime 还保留了一部分页,准备复用或稍后归还。这个时候 heap profile 下降了,RSS 不一定马上跟着下降。
更麻烦的是,RSS 本来就不只包含 Go heap。
它还可能包含:goroutine stack、runtime metadata、二进制映射、cgo 分配、syscall.Mmap、压缩库/图片库的原生内存、文件映射、日志 buffer、甚至 memory-backed emptyDir。
所以 OOM 排查时,不要只拿一张 heap 图说话。你至少要把三条线放在一起:
| |
Go 的 GOMEMLIMIT 约束的也不是“整个进程 RSS”。它的核心口径接近:
| |
对应 runtime/metrics 里常见的说法是:
| |
这就是为什么 GOMEMLIMIT 很有用,但它不是免死金牌。
GOMEMLIMIT 是护栏,不是止血带
Go 1.19 引入 GOMEMLIMIT 之后,容器里的 Go 服务确实好配多了。你可以告诉 runtime:由 Go 管理的内存最好别越过某条软线。
比如容器 limit 是 1Gi,可以从一个保守值开始:
| |
注意,这里的 800MiB 不是官方固定公式。
更准确的说法是:如果 Go 进程基本独占容器内存,且没有大量 cgo、mmap、sidecar、tmpfs,那么 limit * 70-80% 可以作为起点。它的目的不是追求一个漂亮比例,而是给 Go runtime 不统计或控制不了的内存留余量。
如果服务用了 cgo、图片处理、压缩库、大量 TLS buffer,或者 Pod 里还有 sidecar 共享内存,起点就应该更保守。60-70% 也不奇怪。
GOMEMLIMIT 的边界必须讲清楚:
| |
所以线上止血时可以设置 GOMEMLIMIT,但不要把它当修复。
如果根因是全局 map 只增不减,GOMEMLIMIT 只是把事故从“直接 OOM”改成“GC 疯狂工作后再 OOM”。它最多帮你争取时间,不能替你改生命周期 bug。

一个典型时间线:从 OOMKilled 到代码行
把前面的工具串起来,一次完整排查大概是这样。
T+00:00,告警触发。
容器 memory working set 超过 limit 的 90%,持续 10 分钟。p99 从 80ms 涨到 350ms。GC CPU 从 5% 涨到 28%。
先记录现场:
| |
T+00:05,抓第一组样本。
| |
同时看监控:heap live、heap goal、Go managed memory、container working set、goroutine count。
T+00:10,初步分类。
发现 container working set 约 920MiB,heap live 约 430MiB,Go managed memory 约 680MiB,goroutine 数从 800 涨到 11000。
这时候不要急着说“heap 不大,所以不是 Go 的问题”。goroutine 数已经异常,它可能带来 stack scan 增长,也可能持有 request、response、session、buffer,把堆对象间接留住。
T+00:15,抓第二组样本并做 diff。
| |
diff 指向 map[string]*Session 持续增长。goroutine profile 里大量 goroutine 卡在 chan send,创建栈来自同一个请求处理函数。
T+00:25,看代码。
pprof list 里发现两个问题:每个请求都会把 session 放进全局 map,但超时路径没有 delete;另一个 goroutine 往下游 channel 发送时,没有监听 ctx.Done()。
根因不是“GC 太弱”。
根因是 map 只增不减,加 goroutine 生命周期失控。GC 只是把问题暴露出来:存活对象越来越多,扫描成本越来越高,容器内存越来越接近硬 limit。
修复方向也应该落到代码:
| |
再给 session map 增加 TTL 或 size limit,避免同类问题靠“记得 delete”维持。
T+02:00,验证。
你要看的不是“服务没挂了”这么粗的结果,而是修复前后同一组指标:
| |
能通过这组验证,才算排查闭环。
gctrace 适合看趋势,不适合单独定罪
有些线上环境不方便一直开 pprof,但可以在事故窗口临时打开 gctrace。它的好处是轻,不需要图形界面,也不需要你马上把 profile 拉到本地分析。坏处也很明显:它只告诉你 GC 每一轮发生了什么,不告诉你代码里是谁把对象留下了。
启动方式很简单:
| |
一行日志大致长这样:
| |
排查时不要试图把每个字段都背下来。先看四个点。
第一,看 #%。它表示启动以来 GC 消耗的 CPU 比例。如果它从 3% 慢慢涨到 20%、30%,说明 GC 已经开始吃掉明显 CPU。但这仍然是现象,不是根因。
第二,看 #->#-># MB 里的第三个数,也就是 live heap。如果每轮 GC 结束后 live heap 还在涨,说明被判定为存活的对象越来越多。这个时候优先去看 inuse_space 和 profile diff。
第三,看 goal。如果 heap goal 随 live heap 一路抬高,而容器 limit 没有足够余量,后面很容易撞到 OOMKilled。
第四,看 stacks。如果 stacks 也跟着涨,别只盯 heap。goroutine 数可能已经失控,很多“内存泄漏”最后会落到 goroutine 生命周期问题上。
gctrace 最适合回答的问题是:GC 压力是不是越来越重,live heap 是不是越来越大,goroutine stack 有没有可疑增长。
它不适合回答的问题是:哪一行代码泄漏。
这一步还是要回到 pprof。
三类最常见的 Go 泄漏,最后都不是 GC 的锅
Go 里说“内存泄漏”,很多时候不是传统意义上的 malloc/free 忘记释放,而是对象还被引用着。只要还可达,GC 就不能回收。它不是不努力,它是不能删活对象。
第一类是 goroutine 泄漏。
请求超时了,调用方已经走了,下游 channel 还在等发送。或者后台 worker 没有退出协议,ctx cancel 后没人监听。goroutine 本身会占栈,更麻烦的是它栈上可能还挂着 request、buffer、session、logger field 之类的引用。
排查信号通常是:goroutine 数持续涨,profile 里同一类栈越来越多,heap 里还能看到被这些 goroutine 间接持有的对象。
修复方向不是“让 GC 更勤快”,而是让生命周期闭合:监听 ctx.Done(),关闭 channel 有明确归属,worker 有退出路径,关键逻辑加 goleak 测试。
第二类是无界缓存或全局 map。
这类问题最朴素,也最常见。为了省一次查询,把结果塞进 map;为了调试方便,把 session、连接、请求上下文挂到全局结构;为了“以后可能用得上”,只写入不删除。
pprof 里通常会看到 inuse_space 指向 map、slice、cache entry,inuse_objects 也可能一起涨。两次 diff 里如果同一类 key/value 持续为正,就很值得怀疑。
修复方向也很明确:TTL、LRU、大小上限、删除策略。不要让“缓存”变成没有失效规则的垃圾桶。
第三类是高分配速率被误判成泄漏。
比如批量 JSON、压缩、图片处理、日志结构化、临时 buffer。它们可能分配很多,但活得很短。alloc_space 很高,inuse_space 却没有持续增长。这个时候的问题不是“对象没释放”,而是“对象太多,GC 被迫频繁工作”。
优化方向就变了:复用 buffer、减少中间对象、收敛批处理窗口、避免热路径上频繁构造大对象。
这三类问题的处理方式完全不同。混在一起,只会把文章里的“最佳实践”变成线上赌博。
容器配置别只给 limit,不给解释
Kubernetes 里的 request 和 limit 经常被当成 YAML 模板的一部分,复制过去就完事。但 Go 服务的内存问题,很多就埋在这里。
request 主要影响调度。scheduler 会根据 request 判断节点能不能放下这个 Pod。limit 是运行时边界,内存超过 limit 后,kernel/cgroup 可能终止容器。CPU 超 limit 通常是 throttling,内存超 limit 更可能是 OOM kill。
所以 Go 服务的配置至少要留三个意识。
第一,request 不要低到离谱。低 request 会让 Pod 被调度到看似有空间、实际很挤的节点上。平时没事,高峰期节点内存压力一上来,问题就会被放大。
第二,limit 不要贴着稳态均值。Go 服务有 GC 周期,有流量峰值,有临时对象,也有 runtime 自己保留和归还内存的节奏。稳态 700MiB 的服务,给 750MiB limit,看起来省资源,实际上是在逼它贴着悬崖跑。
第三,GOMEMLIMIT 要低于容器 limit,但不能低到让 GC 长期满负荷。它是一道提前减速的护栏,不是越低越安全。设得太低,服务可能还没 OOM,延迟已经被 GC 拖坏了。
一个更稳的起点是:先按历史峰值和业务峰谷给 request/limit,再按非 Go 内存占比给 GOMEMLIMIT 留余量,最后用监控回看它是否真的挡在 OOM 前面。
配置不是写完就结束。它要被验证。
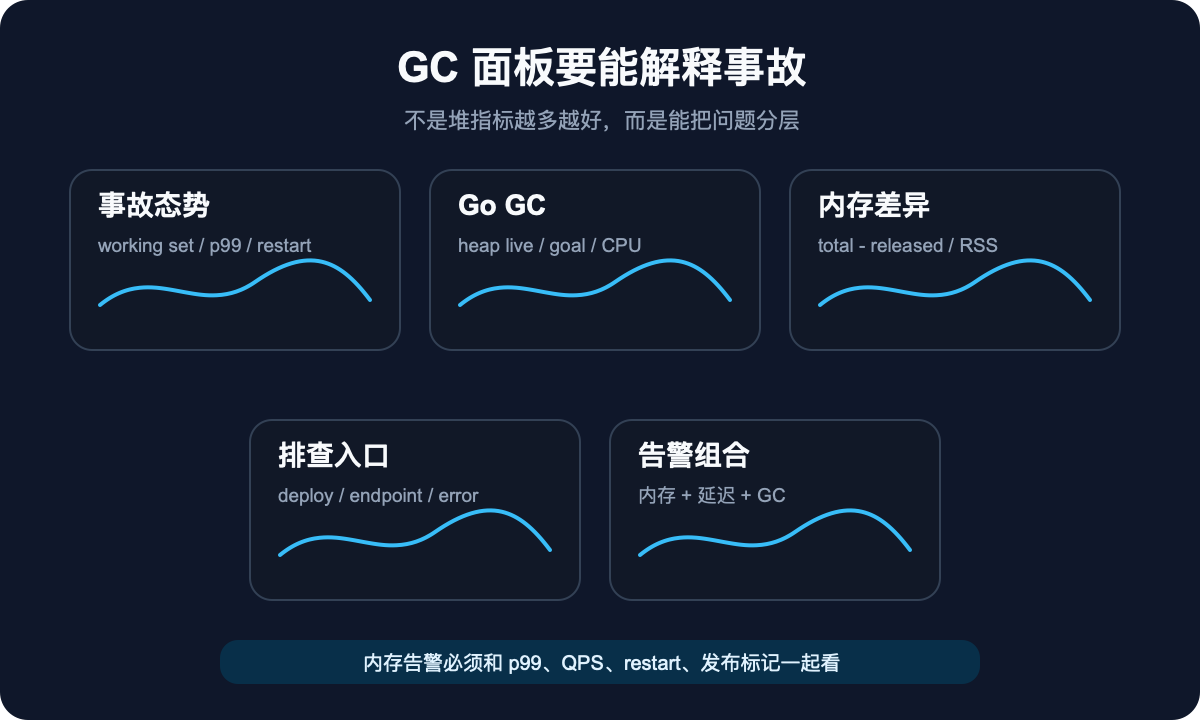
监控面板要能解释事故,不只是好看
很多 Go 服务有 GC 面板,但出事时仍然没人会看。原因是面板只展示指标,没有组织问题。
一个能用于排查的面板,至少要分四层。
第一层看事故态势:
| |
旁边放 p99、QPS、error rate、restart count。先确认这是不是业务事故。
第二层看 Go GC:
| |
再加 GC CPU:
| |
第三层解释内存差异:
| |
再放 heap released、heap objects、goroutine 数。
第四层放排查入口:最近 1 小时发布标记、top endpoint latency、请求量变化、错误类型分布。
告警阈值不要写成绝对真理。更合理的是经验起点:
| |
单独 GC CPU 高,不一定是事故。单独 heap 大,也不一定是泄漏。告警要尽量组合业务指标,否则只会制造噪音。
什么时候可以动参数
说了这么多“别先调参数”,不是说参数不能动。
线上事故里,参数经常要动。只是它应该作为止血或护栏,而不是诊断本身。
几种情况可以考虑先动:
| |
参数调整要小步走。比如 GOGC=100 到 150,再到 200,每一步都看 heap goal、GC CPU、p99、container working set。不要一口气拉到很夸张的值,然后用“暂时没挂”证明它有效。
GOMEMLIMIT 也一样。它不是越贴近 limit 越好,也不是越低越安全。太高,挡不住 OOM;太低,GC 会提前变重。你要找的是服务能接受的那条线。
调参可以救火,但不要让救火动作变成事故结论。
修复以后,要用同一把尺子复测
还有一个容易被跳过的步骤:验证。
很多团队修完内存问题,只看“服务没再重启”就结束了。这个标准太粗。没重启可能只是流量还没回来,也可能是 limit 加大以后把问题藏住了。
更可靠的做法,是用修复前同一套指标复测:
| |
如果修的是 map 只增不减,修复后 inuse_space diff 应该不再持续正增长;如果修的是 goroutine 泄漏,goroutine 数应该回到历史区间;如果优化的是分配速率,alloc_space 热点和 GC cycle rate 应该一起下降。
不要只看一个指标好转。
GOMEMLIMIT 生效以后,GC CPU 可能会上升;limit 调大以后,OOM 可能暂时消失;缓存加 TTL 以后,命中率可能下降。这些都是代价。工程上的修复不是把一条曲线按下去,而是确认系统用你能接受的代价回到稳定状态。
这也是为什么我更建议把排查过程留下来:命令、profile 文件、关键截图、改动前后的指标对比。下一次告警来时,它不是“又出事了”,而是有一条可以复用的路线。
现场文件也要留,不然后面没人信
排查内存问题还有一个很现实的坑:事故过去以后,证据也没了。
Pod 重启了,profile 没抓;日志轮转了,gctrace 没了;Grafana 看得到曲线,但没有保存当时的查询条件。最后复盘只能靠记忆,几个人围着一张截图争论:“当时 heap 到底是不是在涨?”
我建议把现场证据当成交付物留存,至少包括:
| |
这不是流程洁癖。内存问题经常会复发,而且复发时未必是同一个根因。上一次留了证据,下一次就能快速判断:是同一条 map 又涨了,还是这次变成了 RSS 高但 heap 不高。
尤其是 profile 文件,不要只截图。截图只能看结果,profile 才能重新分析。今天你只看了 top,明天可能要看 list、traces、peek。原始文件在,排查才有回头路。
真正成熟的线上排查,不是每次都靠某个高手临场发挥,而是让证据链能被下一个人接着读。
最后:GC 参数不是诊断工具
Go GC 排查最容易犯的错,是把参数当诊断工具。
GOGC 能改变下一轮 GC 来得早还是晚。GOMEMLIMIT 能给 Go runtime 管理的内存加一道软护栏。它们都重要,但它们回答不了“谁把对象留住了”。
谁持有引用、谁没有释放、谁在疯狂分配、谁把 goroutine 卡住了,还是要靠 profile、metrics、trace、代码路径去回答。
一条更稳的线上顺序是:
| |
GC 告警真正的价值,不是提醒你去调 GC。
它提醒你:系统里有一笔内存账,已经没人说得清了。先把账查清楚,再谈调优。