Go 内存为什么不能都怪 GC:goroutine 泄漏、无界缓存和高分配速率修法完全不同
Go 服务内存持续涨,不一定是 GC 的锅。goroutine 泄漏修生命周期,无界缓存修淘汰策略,高分配速率修代码本身——三类问题,三类修法,只有一个共同点:都不该先调 GOGC。
服务又 OOM 了。
Pod 刚重启,群里已经开始出方案:GOMEMLIMIT 设低一点,GOGC 调一下,limit 先加 1Gi,GC 日志再翻一遍。
这些动作有时候能救火,但经常救不到根上。
因为很多 Go 服务所谓的“内存泄漏”,根本不是一种病。goroutine 卡住、全局 map 只增不删、热路径疯狂分配,看起来都像内存曲线往上走,修法却完全不同。
你把它们都叫 GC 问题,排查就会变成调参赌博。
GC 不是清洁工,它不能删除还被引用的对象。
这篇不再重复讲 OOMKilled 第一现场怎么确认。上篇已经讲过:先看谁被杀、撞到什么 limit、heap 和 RSS 是不是同一本账。这篇往下走一步:当你确认 Go 服务确实有内存压力,怎么把“泄漏”拆成三类。
拆清楚以后,很多争论会少一半。
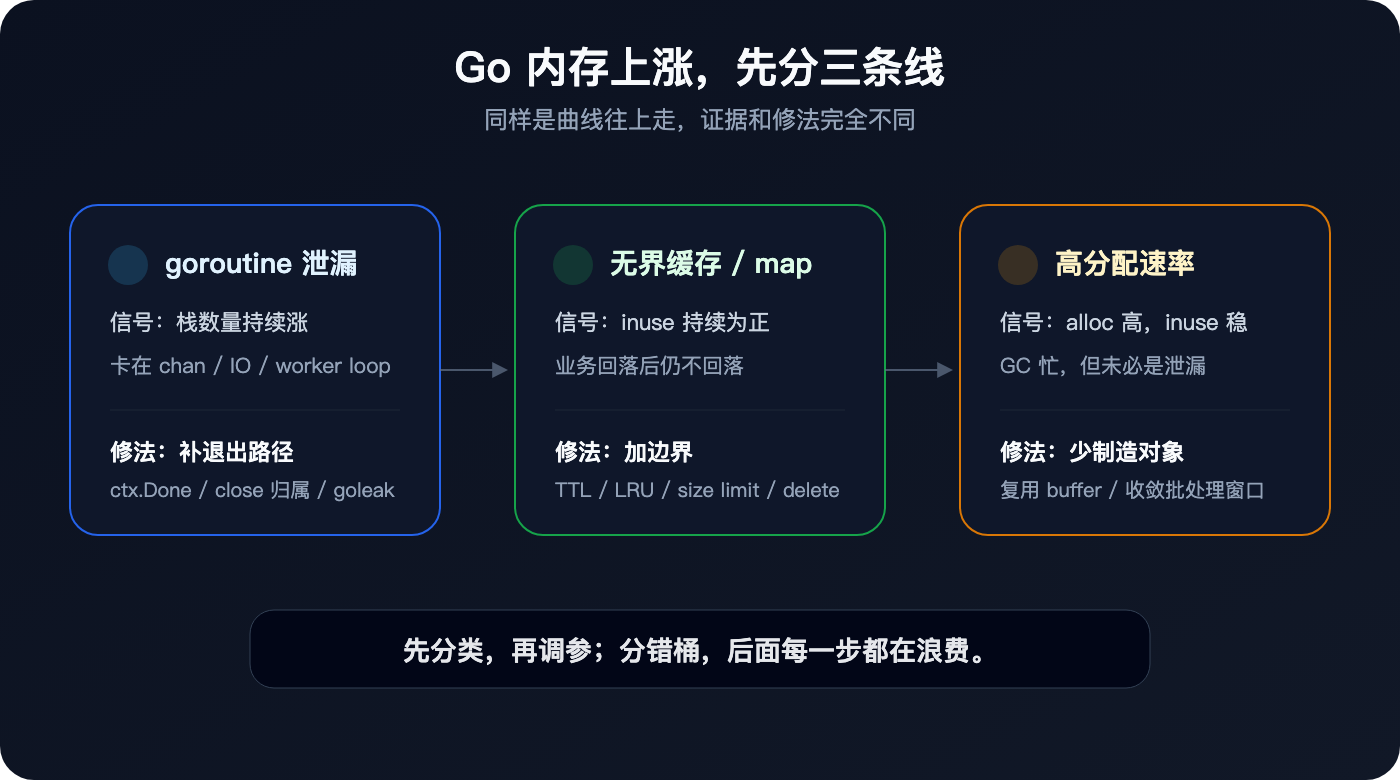
第一类:goroutine 泄漏,真正漏的是生命周期
goroutine 泄漏最容易被低估。
很多人听到 goroutine,会觉得它很轻:几 KB 栈,问题不大。但线上事故里,麻烦通常不只是 goroutine 自己占多少内存,而是它还挂着什么。
请求已经超时了,调用方走了,下游 channel 还在等发送;context 已经 cancel 了,后台 worker 还在跑;连接断了,读循环没有退出;定时任务里起了 goroutine,却没有任何关闭协议。
这些 goroutine 还活着,栈上可能就挂着 request、response、session、buffer、logger field、trace span。
对象还被引用着,GC 就不会删。
排查信号通常很直接:
| |
事故现场不要只抓 heap。goroutine profile 要一起留:
| |
然后看两件事:同一类栈是不是在增长,创建点是不是集中在某条业务路径。
常见修法不是调 GC,而是补生命周期:
| |
这个例子不复杂,但它代表一个原则:所有可能阻塞的 send、recv、IO、worker loop,都要知道自己什么时候该退出。
如果你只把 GOGC 调低,GC 会更频繁地扫描这堆仍然“活着”的对象。它更累,但问题还在。
goroutine 泄漏的修复,最后往往落在几件小事上:监听 ctx.Done(),明确 channel 关闭归属,worker 有退出路径,关键逻辑加 goroutine leak 测试。
它不是 GC 参数问题。
它是你没有把一个任务从出生到死亡安排完整。
第二类:无界缓存和全局 map,最朴素,也最危险
第二类更常见:缓存没有边界,全局 map 只写不删。
为了少查一次数据库,把结果塞进 map;为了排查方便,把 session、连接、请求上下文挂到全局结构;为了“后面可能用得上”,先 append 到 slice 里,删除策略以后再说。
这个“以后”,线上通常等不到。
pprof 里你会看到 inuse_space 指向 map、slice、cache entry,inuse_objects 也可能一起涨。更关键的是,两次 profile diff 里,同一类对象持续为正。
要看增长,不要看截图:
| |
如果某个 map[string]*Session 一直涨,或者某类 cache entry 在业务回落后还不回落,方向就很明确了。
修法也别绕。
缓存必须有 TTL、LRU、大小上限、主动删除策略。全局 map 必须有清理路径。session、连接、请求状态这种东西,生命周期不能只靠“正常路径会 delete”。超时、失败、取消、panic 后恢复,这些路径都要算进去。
| |
这段代码不是说 defer Delete 就包治百病。真正要看的,是所有写入全局结构的地方,有没有对应的释放策略;所有缓存,有没有容量和过期;所有异常路径,有没有被纳入生命周期。
很多团队喜欢给缓存起很漂亮的名字:本地加速层、热点数据池、临时状态表。
名字没用。
没有失效规则的缓存,就是一座垃圾场。
这类问题用 GOMEMLIMIT 也挡不住。它可能让 GC 提前加压,让事故晚一点出现,但如果 live heap 本身一直涨,最后只是把“直接 OOM”变成“GC 疯狂工作以后再 OOM”。
参数能争取时间,不能替你设计生命周期。
第三类:高分配速率,不一定是泄漏
第三类最容易冤枉人。
你打开 pprof,看到某个 JSON 编码、压缩、日志拼接、图片处理函数排在 alloc_space 前面,于是马上说:这里泄漏了。
不一定。
alloc_space 高,只说明它累计分配多。它没有告诉你这些对象现在还活着。
批量 JSON、压缩、结构化日志、临时 buffer、请求中间对象,都可能在短时间内制造大量分配。但请求结束后对象就该被回收。这个时候 alloc_space 很高,inuse_space 可能很平稳。
这不是“对象没释放”,而是“对象太多,GC 被迫频繁工作”。
判断这类问题,先把三个视角分开:
| |
如果 alloc_space 高、GC CPU 高、p99 变差,但 live heap 没有持续抬升,优化方向就不是“找谁没释放”,而是减少分配。
比如:
| |
实际项目里未必就该上 sync.Pool。它有代价,也可能让代码更复杂。重点不是这段代码,而是判断路径:如果问题是高分配速率,你要减少热路径临时对象、复用 buffer、收敛批处理窗口、避免频繁构造大对象。
这和修全局 map 泄漏,是两件事。
一个是对象不该继续活着。
一个是对象活得不久,但出生得太多。
别把这两种问题混在一起。混在一起以后,最常见的错误就是:明明该优化分配速率,却去找“泄漏对象”;明明是全局引用留住对象,却去调 GOGC。
GOMEMLIMIT 是护栏,不是止血带
Go 1.19 以后,GOMEMLIMIT 对容器里的 Go 服务很有价值。
它让你可以告诉 runtime:由 Go 管理的内存,尽量不要越过某条软线。比如容器 memory limit 是 1Gi,服务基本独占容器内存,没有大量 cgo、mmap、sidecar、tmpfs,可以先从一个保守值开始观察:
| |
这里的 800MiB 不是官方固定公式。更稳的说法是:如果 Go 进程基本独占容器内存,可以把 container limit 的 70%-80% 当起点,给非 Go 内存、runtime 保留、内存尖峰留余量。
如果服务用了 cgo、图片处理、压缩库、大量 mmap,或者 Pod 里还有 sidecar,共享 emptyDir 也吃内存,那就要更保守。
GOMEMLIMIT 的边界必须讲清楚:
| |
GOMEMLIMIT 是护栏,不是止血带。
护栏的作用,是在车快冲出路面前提醒你减速。它不能修刹车,不能补轮胎,也不能把已经失控的车变回正常。
什么时候可以先用它?
事故窗口里,container working set 已经贴近 limit,Go managed memory 又确实占了大头,而服务还要撑过高峰,这时设一个保守的 GOMEMLIMIT 是合理的。它能让 GC 更早介入,尽量把 Go runtime 管理的内存压在更安全的位置。
但你要同时盯住代价:GC CPU 有没有上去,p99 有没有变差,heap live 有没有真的回落。如果只是 GC 更忙、延迟更差、live heap 还在涨,那它已经不是修复动作,只是报警器叫得更早。
所以线上可以用它止血,但不要把“设了 GOMEMLIMIT”写进根因修复。
根因修复还是要回到三类问题:goroutine 生命周期有没有闭合,缓存和 map 有没有边界,热路径分配是不是过高。
K8s 配置最怕“看起来省资源”
Kubernetes 里的 request 和 limit 很容易被当成模板复制。
但 Go 服务的内存事故,很多就埋在这里。
request 主要影响调度。scheduler 会根据 request 判断节点能不能放下这个 Pod。limit 是运行时边界。内存超过 limit 后,容器可能被 OOM kill;CPU 超 limit,通常表现为 throttling。
几个坑很常见。
第一,request 给得太低。
Pod 被调度到看起来有空间、实际很挤的节点上。平时没事,高峰期节点内存压力上来,问题被放大。
第二,limit 贴着稳态均值。
一个稳态 700MiB 的服务,limit 给 750MiB,看起来省资源,实际上是在逼它贴着悬崖跑。Go 服务有 GC 周期,有流量峰值,有临时对象,也有 runtime 保留和归还内存的节奏。你不能只看平均值。
第三,GOMEMLIMIT 设得太低。
太高挡不住 OOM,太低会让 GC 过早变重。服务可能还没被杀,p99 已经被 GC 拖坏了。
更稳的起点是:先按历史峰值和业务峰谷给 request/limit,再按非 Go 内存占比给 GOMEMLIMIT 留余量,最后用监控看它有没有挡在 OOM 前面。
配置不是写完就结束。
它要被验证。
验证也别只看“没再 OOM”。这句话太粗了。limit 加大以后当然可能不 OOM,问题也可能只是被藏起来了。你至少要回看三条线:container working set 峰值有没有离 limit 远一点,GC CPU 有没有因为 GOMEMLIMIT 过低被拉高,p99 有没有在高峰期一起变差。
如果改的是缓存策略,还要看命中率和回源压力;如果改的是 goroutine 退出路径,要看 goroutine 数是否回到历史区间;如果改的是分配速率,要看 alloc 热点和 GC cycle 是否一起下降。
修复不是把一条曲线按下去。
修复是确认系统用你能接受的代价,回到稳定状态。
监控面板要解释事故,不只是摆指标
很多团队有 Go GC 面板,但出事时还是没人会看。
原因是面板只展示指标,没有组织问题。
一个能用于排查的面板,至少要能回答四层问题。
第一层:事故有没有发生。
| |
旁边放 p99、QPS、error rate、restart count。先确认这是不是业务事故,不要只盯内存曲线自嗨。
第二层:Go heap 和 GC 压力有没有变化。
| |
GC CPU 可以看:
| |
第三层:Go 管理的内存和容器账本差多少。
| |
再放 heap released、heap objects、goroutine 数。
第四层:排查入口。
最近一小时发布标记、top endpoint latency、请求量变化、错误类型分布。否则你只知道曲线变了,不知道它和哪次发布、哪类请求、哪个流量峰有关。
告警阈值不要写成绝对真理。可以先用经验起点:
| |
这些数字不是法律。它们只是帮你把“感觉不对”变成“该看哪条线”。真正的告警要结合业务指标,否则只会制造噪音。
泄漏排查不是找一个最大数字,然后宣布破案。
它是把每个数字放回自己的账本里:goroutine 数解释生命周期,inuse 解释谁还活着,alloc 解释谁一直在制造对象,RSS 解释容器和系统看到的总账。
最后:先分类,再动手
下次 Go 服务内存一直涨,不要急着把锅甩给 GC。
先问三个问题:
| |
答案不同,修法就不同。
goroutine 泄漏,修退出路径。无界缓存和全局 map,修生命周期和容量边界。高分配速率,修热路径分配。GOMEMLIMIT 和 GOGC 可以作为护栏和止血动作,但它们不是根因修复。
参数可以救火,不能替你破案。
真正成熟的排查,不是把某个参数背得很熟,而是能在事故现场把问题分到正确的桶里。分错桶,后面每一步都可能很努力,也很浪费。
如果你也在排查 Go 服务的内存问题,可以先收藏这套判断法。下次群里有人说“先调一下 GC”,你至少可以把问题拉回来:
先别急。我们先看它到底是哪一种漏。