Go GC 为什么不能只看 STW:三色标记和写屏障才是你该先算的账
很多人盯着 STW 的微秒级停顿不放,却忽略了并发标记才是 GC 真正吃掉 CPU 的地方。三色标记解决的不是颜色问题,是并发安全;写屏障也不是玄学,是防止漏标的保险。
服务内存从 800MB 慢慢涨到 2.6GB。
曲线不陡,不像雪崩。它只是每天往上爬一点,重启以后掉下来,过几天又回到老地方。告警一响,群里很快会出现两个动作:先怀疑泄漏,再问 GOGC 要不要调。
这两个反应都不离谱,但都太早。
在 Go 服务里,内存涨可能是真泄漏,也可能只是 live heap 变大了;可能是分配速率太高,也可能是 GC 目标允许堆多长了一段;还有一种常见误会:堆已经回收了,但 RSS 没有按你期待的节奏马上降下去。
真正要命的不是内存涨,而是你把 GC 当黑箱。
一旦把它当黑箱,排查就会变成猜参数:GOGC 调大一点?调小一点?要不要加 GOMEMLIMIT?要不要手动 runtime.GC()?
这些动作不是不能做。问题是,在你没看懂 GC 正在算什么账之前,调参很容易变成给线上服务摇骰子。
GC 不是保洁员,是成本调度器
很多人对 GC 的第一印象是“内存不用了,运行时帮我扫掉”。这个说法只说中了一半。
另一半更重要:GC 每工作一次,都要付成本。
扫得太勤,CPU 被回收器吃掉,吞吐会掉,延迟也可能抖。扫得太晚,内存峰值会上去,容器可能还没等你优雅回收,就先把进程杀掉。
所以 Go GC 不像保洁员,看到垃圾就立刻冲上去扫。它更像一个拿着预算表的人:上一轮还有多少对象活着?这轮又分配了多少?再拖一会儿,内存扛不扛得住?现在开始扫,CPU 又吃不吃得消?
GC 调的不是洁癖,是成本。
GOGC 就是这笔账里最常见的旋钮。
GOGC=100 不是“内存到 100MB 就触发 GC”。它更接近一个增长比例:在上一轮存活堆的基础上,允许新分配的堆内存再长一段,再启动下一轮 GC。Go 官方 GC Guide 给出的目标堆公式可以简化理解为:
| |
这里有个很容易误会的地方:这个目标不是你容器的内存上限,也不是进程 RSS 上限。它只是运行时决定“什么时候该开始下一轮 GC”的一个目标。
GOGC 从 100 调到 200,GC 可能少跑几次,CPU 压力可能小一点,但内存峰值会更高。调到 50,内存可能收得更紧,但 GC 会更勤。
所以看到内存上涨,不要上来就问“GC 参数该设多少”。更好的问题是:现在买不起的是内存,还是 CPU?
这两个答案会把你带向完全不同的动作。内存买不起,可能要把回收目标收紧,或者给容器场景补上合理的内存软上限。CPU 买不起,可能要减少分配、复用对象,或者在内存还有余量时让 GC 少跑几次。更糟糕的是两个都买不起:内存贴着上限跑,CPU 也被 GC 吃掉。这时再随手调一个参数,往往只是把压力从一边挪到另一边。
所以调参前,先把账本摊开。别把“看起来有动作”,当成“真的在解决问题”。这一步真的省不掉。
这个问题不问清楚,后面的动作都可能是错的。
三色标记解决的不是颜色问题
GC 要回收对象,第一步不是“清理”,而是判断对象还活不活。
Go 的 GC 属于 tracing GC。它从一组 roots 出发,比如全局变量、goroutine 栈上的指针、寄存器里的引用,沿着指针一路往下找。能被找到的对象,叫可达;找不到的对象,才有机会被当成垃圾。
这件事听起来简单,真正难的是:业务还在跑。
如果整个世界都停住,GC 从 roots 一路扫完,标出活对象,再把没标上的清掉,这就是一件机械活。但线上服务不是标本。请求还在进来,goroutine 还在执行,map、slice、struct 里的指针还在被改。
三色标记就是为了描述这个动态过程。
- 白色:还没确认可达。标记结束后仍是白色,才可能被清理。
- 灰色:已经确认可达,但它指向的对象还没完全扫完。
- 黑色:已经确认可达,并且它指向的对象也扫过了。
灰色对象可以理解成待办队列。GC 从 roots 出发,把能碰到的对象变灰;再不断取出灰色对象,扫描它的指针,把它指向的白色对象也变灰;扫完以后,这个对象变黑。
如果应用不再改指针,这套流程没什么悬念。
麻烦就出在这里:应用会改。
标记期间,业务还在写指针
危险场景很具体。
一个对象已经被 GC 扫完,变成黑色。按 GC 的理解,它的指针关系已经检查过了。结果这时业务代码继续运行,把这个黑色对象里的某个字段,改成指向另一个白色对象。
如果这个白色对象没有其他灰色路径能被扫到,GC 就可能漏掉它。
漏标不是“回收慢一点”。漏标意味着对象明明还活着,却可能被当成垃圾处理。
这不是性能问题,这是正确性问题。
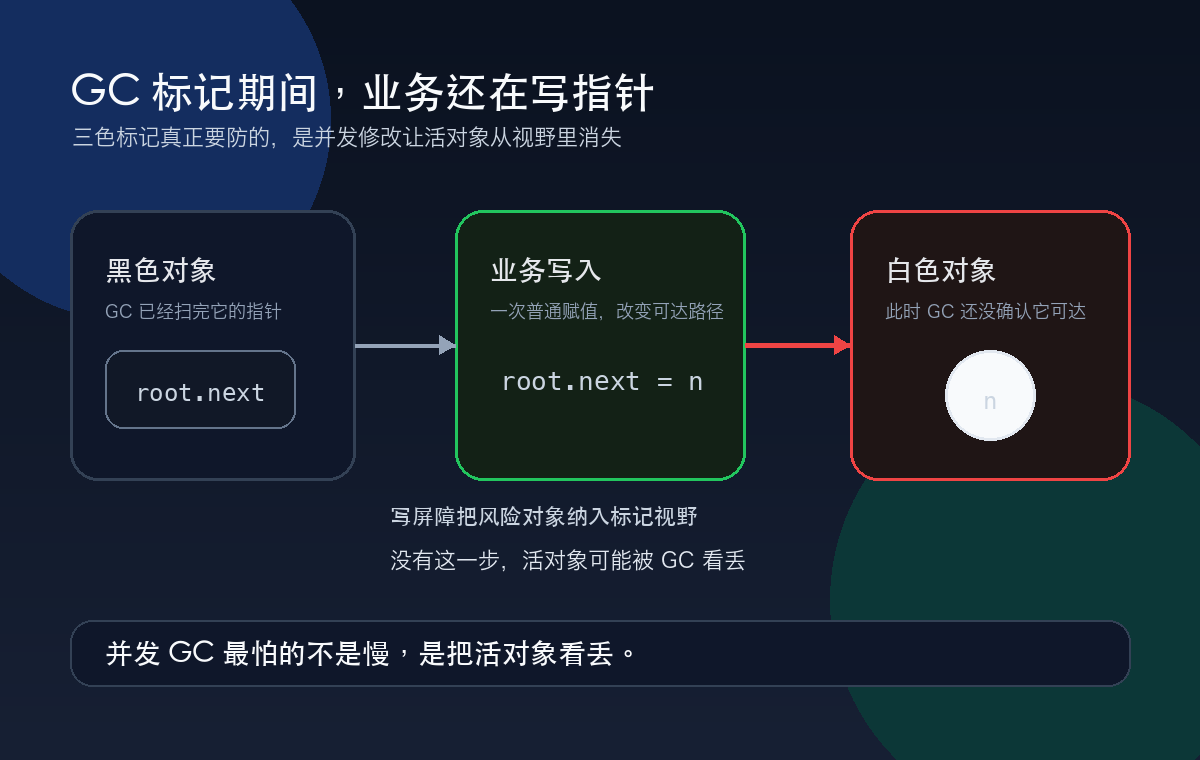
这也是很多人学三色标记时真正卡住的地方:颜色本身不难,难的是颜色会在业务运行中被打乱。
并发 GC 最怕的不是慢,是把活对象看丢。
你可以把这个问题放进一段很普通的业务代码里看:
| |
平时这就是一次普通赋值。但如果它发生在 GC 并发标记期间,含义就不一样了:root 可能已经被扫成黑色,n 可能还是白色。业务眼里只是改了一个字段,GC 眼里却可能多出一条新的可达路径。
如果运行时不管这次写入,标记结果就不再可信。
所以只要允许业务和 GC 并发执行,就必须有一套保险,保证业务修改指针时,GC 的标记结果仍然成立。
这个保险就是写屏障。
写屏障不是玄学,是业务写指针时插一脚
写屏障这个名字很容易吓人,好像是某种虚拟机黑魔法。其实它做的事很朴素:在 GC 标记期间,业务代码修改指针时,运行时插入一小段额外逻辑,防止 GC 漏标。
你可以把它理解成一个门卫。
业务说:“我要把这个字段改成指向新对象。”
门卫拦一下:“现在 GC 正在标记,你这个新指针会不会让某个白色对象突然变成活对象?如果会,得把它纳入标记视野。”
业务又说:“我要覆盖旧指针。”
门卫再看一眼:“旧对象会不会因为这次覆盖,从 GC 视野里掉出去?如果有风险,也得保住。”
具体实现当然比这个比喻复杂。Go 1.8 使用混合写屏障,目标之一就是减少过去需要 STW 重新扫描栈带来的停顿。工程排查时,不必把每个屏障细节背成口令,先抓住这个判断就够了:
写屏障不是为了让 GC 看起来高级,而是为了让业务一边写指针,GC 一边标记时,运行时仍然不会误删活对象。
当然,保险不是免费的。
标记期间,指针写入会多一些额外成本。大多数业务不会因为这点成本单独出问题,但如果你的高峰期本来就在疯狂分配、疯狂改指针、疯狂构造临时对象,GC 的存在感会被放大:CPU 上去,吞吐掉一点,gctrace 变密,p99 开始不稳。
这时不要急着骂 GC。
GC 只是把你分配对象的成本,换了一种方式寄账单。
STW 可怕的不是存在,是你没量过
Go GC 不是整轮都 stop-the-world。它主要并发执行,但仍然需要很短的停顿来完成阶段切换。
可以粗略看成这几段:
- Mark setup:短暂停顿,打开写屏障,准备进入并发标记。
- Concurrent mark:应用继续运行,GC 并发扫描可达对象。
- Mark termination:短暂停顿,完成标记收尾,关闭写屏障。
- Sweep:清扫未标记对象,通常和应用并发推进。
Go 1.8 release notes 里提到,GC pause 相比 Go 1.7 明显缩短,通常低于 100 微秒,并且消除了 stop-the-world stack rescanning。这是 Go GC 演进里非常关键的一步。
但这句话不能拿来当线上免死金牌。
你的服务到底停了多久,还是要看自己的数据。goroutine 数量、堆大小、对象图形态、Go 版本、CPU 状态,都会影响最终延迟。
最小观察方式,是先打开 gctrace:
| |
你会看到类似这样的输出:
| |
不用一开始就背完整格式。排查时先看四件事:
64->72->38 MB:GC 前、GC 后、存活堆大概是什么变化。76 MB goal:下一轮目标堆大概是多少。0.021+4.3+0.065 ms:两端短暂停顿和中间并发标记的大致耗时。2%:GC 占用 CPU 的大致比例。
如果 GC 后 live heap 仍然一路上升,优先查对象为什么还活着:全局 map、缓存淘汰、goroutine 泄漏、引用链没断,都比调参数更值得看。
如果 live heap 能降下来,但 GC 很密,优先查分配速率:热路径里的临时 slice、map、JSON 编解码、日志字段拼装,都可能把 GC 喂得很饱。
如果 STW 很短但 p99 仍然抖,也别把 pause 当唯一嫌疑人。标记期 CPU、GC assist、锁竞争、调度延迟,都可能一起参与了这次抖动。
这里还有一个很常见的误动作:看到内存高,就想在代码里塞一个 runtime.GC()。
它看起来很果断,实际经常是在制造新的不确定性。手动 GC 会强行触发一轮回收,但它不会改变对象可达性,也不会降低你的分配速率。业务对象如果还被全局 map、缓存、goroutine、闭包或 channel 链路拉住,手动 GC 再勤也收不掉。热路径如果一直在造短命对象,手动 GC 也只是把账单提前结一次。
更麻烦的是,这种动作会让排查变浑。你以为自己在验证 GC,实际是在改变现场:GC 频率变了,CPU 曲线变了,延迟也可能被你打出新的尖刺。最后看图的时候,已经分不清哪些是业务原本的问题,哪些是你刚刚按下去的按钮制造出来的波动。
所以,除非你非常清楚自己在做实验,否则不要把 runtime.GC() 当成线上止血按钮。
GC 问题最怕的不是不会调参数,是还没分清“对象活着”和“回收不积极”这两件事。
下次内存涨,先别急着动参数
回到开头那条内存曲线。
服务从 800MB 涨到 2.6GB,第一反应可以怀疑泄漏,但不要停在怀疑。你要把问题拆开:对象是不是还可达?分配是不是太快?GC 目标是不是放得太宽?RSS 和 heap profile 是不是在说同一件事?
更稳的顺序是:
- 看 GC 后 live heap 有没有持续上升。
- 看分配速率是不是把 GC 推得太勤。
- 看 STW、GC CPU 和 p99 是否真的同步恶化。
- 最后再决定要不要动
GOGC或GOMEMLIMIT。
参数当然有用,但它不该是第一把刀。
GC 能回收不可达对象,不能替你判断业务对象该不该活着。
三色标记、写屏障、STW 这些词,单独背下来没什么用。它们真正的价值,是让你看懂 Go runtime 在并发世界里怎么保证正确性,又把 CPU、内存和延迟之间的代价摆到你面前。
下篇继续往下走:GOGC 和 GOMEMLIMIT 到底该怎么配,线上看到内存上涨时,怎样用 pprof、gctrace 和运行时指标把"泄漏、分配过猛、参数不合适"分开。
如果你觉得有收获,可以点个关注。这个系列会沿着 GC 的源码和线上排查继续拆下去。