Go GC 占 CPU 5%,到底要不要调 GOGC?
从 p99 周期性抖动和 GC CPU 5% 的真实场景出发,讲清 GOGC、GOMEMLIMIT、STW、gctrace 和容器环境下的 Go GC 调优顺序。
服务 p99 每隔几十秒抖一下。
监控里 GC CPU 大概 5%,不算夸张,但曲线很准:GC 一来,延迟就往上冒。群里很快有人提议:把 GOGC 从 100 调到 200,先让 GC 少跑几次。
这个动作看起来很合理。
CPU 下来了,GC 日志没那么密了,p99 也安静了几天。然后另一个问题来了:容器内存开始逼近 limit,某个高峰期被 OOMKilled。大家又把 GOGC 调回去,延迟抖动也跟着回来。
这就是很多 Go GC 调优的真实状态:不是不会调参数,而是没想清楚自己到底在买什么。
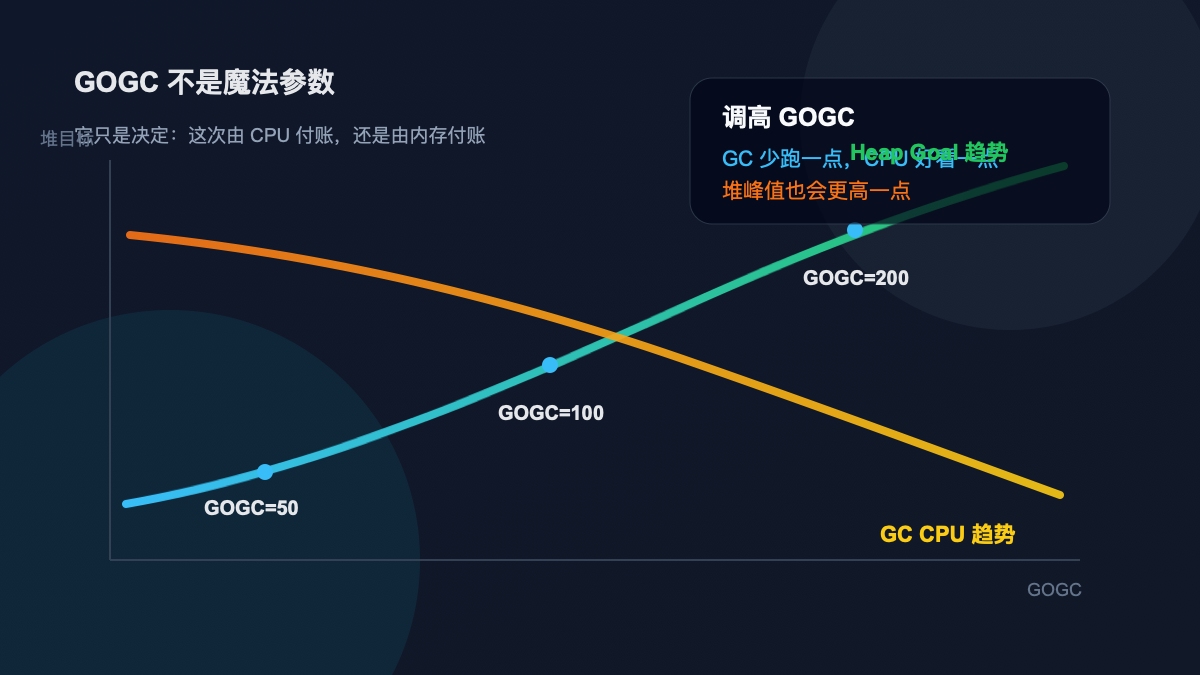
GOGC 调的是账期,不是魔法。
调高它,相当于允许堆多长一段时间,用内存换 CPU;调低它,相当于让 GC 更勤快,用 CPU 换内存。至于 GOMEMLIMIT,它不是另一个版本的 GOGC,而是在告诉 runtime:这个进程由 Go 管的内存,最好别越过这条线。
所以这篇不打算把 GC 参数逐个解释一遍。线上真正需要的是一条决策路径:要不要调,调什么,调多少,什么时候停手。
先别问 GOGC 设多少,先问谁在付账
Go 官方 GC Guide 给过一个很关键的公式:
| |
这句话不用背,抓住意思就行。
上一轮 GC 结束后,还活着的对象叫 live heap。GOGC 决定的是:在这些活对象基础上,允许新分配再增长多少,下一轮 GC 才开始。Go 1.19 之后,GC roots 的成本也会纳入目标计算,所以 goroutine 栈、全局变量这些根对象不是“免费背景”。
假设 live heap 是 512MiB,先忽略 roots 的影响:
| |
这就是为什么 GOGC=200 经常能让 GC 看起来“轻”一点。不是 GC 变聪明了,而是你允许它晚点再来。
晚点再来,CPU 通常好看一些;代价是堆峰值更高。早一点来,内存收得紧;代价是 GC 更频繁,CPU 和 mutator assist 的存在感更强。
GC 调优不是消灭 GC,而是决定谁来付账。
如果 CPU 是瓶颈,内存很宽裕,提高 GOGC 有机会换来吞吐。如果内存已经贴近容器上限,提高 GOGC 就是在把风险往 OOM 那边推。如果 live heap 本来就在涨,调 GOGC 更像是把账单推迟几分钟,不是把问题解决了。
GOGC=200 为什么会好几天,又突然出事
线上最迷惑人的地方,是参数调整经常短期有效。
服务 GC CPU 5%,p99 周期性抖。你把 GOGC=100 改成 GOGC=200,GC 频率降了,业务 goroutine 被 GC 抢走的时间少了,图上很容易出现“优化成功”的错觉。
但堆目标也被抬高了。
如果服务有大块临时对象,比如批量 JSON、图片处理、压缩缓冲、消息批处理窗口,调高 GOGC 后,更多 dead-but-not-yet-collected 的对象会在堆里多待一会儿。它们已经没用了,但下一轮 GC 还没来。
在裸机上,这可能只是 RSS 曲线难看一点。在容器里,它可能直接变成 OOMKilled。
这也是为什么容器场景里不能只谈 GOGC。Kubernetes 不关心你的 heap goal 是怎么计算的,它只看 cgroup 里的内存使用。超过 limit,进程就可能被杀。
所以判断 GOGC 能不能调高,要同时看几条线:
| |
如果 GC CPU 高,但 live heap 稳定、RSS 很宽裕,提高 GOGC 可以试。比如从 100 到 150,再到 200,边调边看。
如果 RSS 已经紧张,或者容器经常被内存打满,别急着调高 GOGC。这时候你要先设内存边界。
GOMEMLIMIT 是边界,不是免死金牌
Go 1.19 引入 GOMEMLIMIT 后,容器里的 GC 调优舒服了很多。
以前只有容器 memory limit,Go runtime 并不知道外面那条线在哪里。它只按自己的 heap goal 和 pacer 工作。现在你可以告诉 runtime:由 Go 管理的内存最好控制在某个软上限内。
| |
代码里也能动态改:
| |
这里有两个坑,必须说清楚。
第一,GOMEMLIMIT 是 soft limit,不是硬墙。它约束的是 Go runtime 管理的内存,官方口径接近:
| |
它不覆盖所有东西。cgo 分配、某些 mmap、内核态开销、外部库、文件缓存、sidecar 影响,都可能不在这条账里。
第二,不要把容器 1GiB limit 直接写成 GOMEMLIMIT=1GiB。这等于不给 Go 之外的内存留空间。
很多工程实践会先留 20% 到 30% 的余量,比如 1GiB 容器先设 700MiB 到 800MiB,再根据实际 RSS、堆、cgo、流量峰值微调。但这个比例不是 Go 官方定律。Go 官方更明确的提醒是:给非 Go runtime 管理的内存留 headroom。
容器里先设内存边界,再谈吞吐野心。
比较稳的起点是:
| |
如果服务没有 cgo、没有大 mmap、对象模型比较单纯,余量可以少一点。反过来,如果服务依赖图像库、压缩库、向量索引、数据库驱动里有明显的 Go 外内存,就别把 GOMEMLIMIT 贴得太满。
GOMEMLIMIT 不是 OOM 保险箱。它只是让 runtime 更早知道边界在哪里。
STW 很短,不等于 GC 没影响
很多人看 gctrace,第一反应是找 STW。
这没错,但容易查偏。
Go GC 不是整轮 stop-the-world。它主要并发执行,通常只有阶段切换时需要短暂停顿。可以粗略看成几段:
| |

你在 gctrace 里会看到类似这样的输出:
| |
先抓三个地方:
| |
第一组数字里,两端通常对应短暂停顿,中间是并发阶段的 wall time。第二组是 GC 前、GC 后、存活堆。第三个是下一轮目标堆。
有些服务里,mark setup 和 mark termination 可能只是几十微秒。看起来很短,于是有人下结论:p99 抖动不是 GC。
这个结论太快了。
STW 很短,不等于 GC 没影响。
因为 p99 抖动不只来自 pause。并发标记会吃 CPU,mutator assist 会让业务 goroutine 帮 GC 干活,写屏障会让标记期的指针写入多一点成本。高分配速率下,应用自己把 GC 喂得太饱,即使 STW 很短,业务线程也可能在标记期感到“变重”。
所以排查延迟时,不要只问“pause 有多长”。更应该问:
| |
如果 pause 很短,但 GC 期间 CPU 明显上升,p99 仍然贴着 GC 周期抖,你就不能把 GC 排除掉。
三种场景,调法完全不一样
我在本机做了一组短跑实验,只用来说明趋势,不当成任何官方 benchmark。
环境是 Apple M1 Pro,GOMAXPROCS=4,同一份 benchmark 分别跑 GOGC=50/100/200。三个场景:高频小对象、大对象保留窗口、少分配计算。
高频小对象结果大致是:
| |
大对象保留窗口:
| |
少分配计算:
| |
gctrace 行数也能看出趋势:
| |
这些数字不要外推。换机器、换 Go 版本、换对象结构,绝对值都会变。但趋势有参考价值:
高频小对象分配,GOGC 调高可能让 GC 少跑,吞吐好看一点。但这不是根治。真正该改的是分配本身:少用热路径 fmt.Sprintf,减少临时 slice/map,复用 buffer,避免不必要的 interface 装箱和反射。
大对象场景,尤其是 []byte 这类少指针对象,mark 扫描成本未必和字节数同比增长,但 RSS 和 heap peak 会很敏感。这里调高 GOGC 很容易抬高峰值,容器里必须和 GOMEMLIMIT 一起看。
少分配场景,别迷信调 GC。allocs/op 接近 0 的代码,GOGC 很可能不是瓶颈。你应该看锁、I/O、算法、调度,而不是对着 GC 参数拧来拧去。
真正实用的是这条决策路径
我更建议把 Go GC 调优压成一条简单路径。
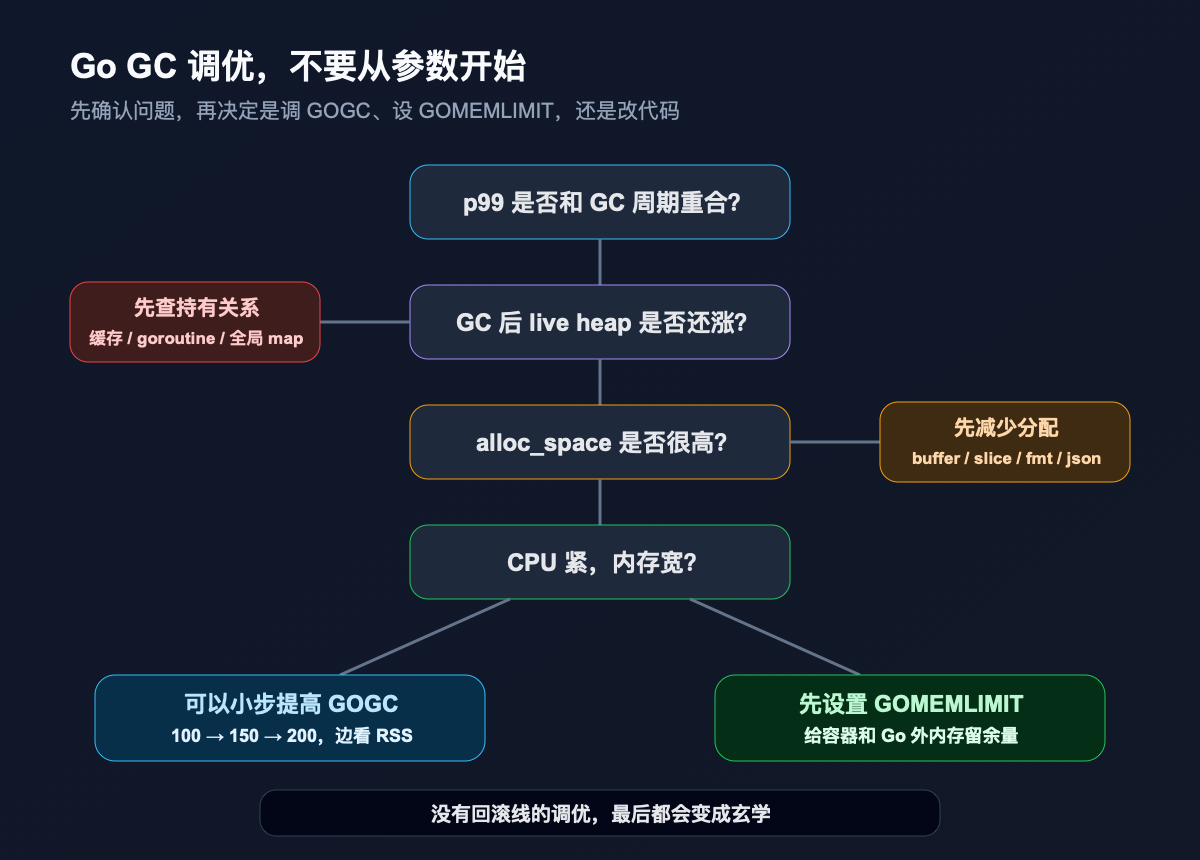
第一步,确认 GC 是不是问题。
别只看 GC CPU 百分比。5% 不一定高,1% 也不一定没事。关键是它和业务指标有没有关系。
| |
同时看 p99、吞吐、CPU、RSS、heap profile。GC 周期和 p99 抖动重合,才值得继续往下查。
第二步,看 live heap。
| |
如果 GC 后 live heap 还一路涨,优先查对象为什么还活着。缓存没有淘汰、全局 map 持有、goroutine 泄漏拉住上下文、channel 阻塞导致请求对象释放不了,这些都不是 GOGC 能救的。
GC 只回收不可达对象。业务还拉着引用,GC 不会替你做判断。
第三步,看分配速率。
| |
如果 inuse 不高,但 alloc_space 很难看,说明短命对象太多。这个时候调大 GOGC 可以减少 GC 频率,但本质是延期还债。该减少分配就减少分配。
第四步,再决定参数。
| |
第五步,给自己设回滚线。
任何 GC 参数调整,都应该提前写清楚观察窗口和回滚条件:
| |
没有回滚线的调优,很容易变成玄学。
gctrace 不够,还要把 runtime 指标接上
gctrace 很适合临时排查,但它不是长期观测方案。线上服务真正要稳定调 GC,最好把 runtime 指标接进 Prometheus、OpenTelemetry 或你们自己的 metrics 系统。
最少要看这些:
| |
如果你还在用 runtime.ReadMemStats,也不是不能用。先把下面几项打出来,已经能救很多排查现场:
| |
看这些指标时,不要孤立看某一个值。
HeapAlloc 上升,说明当前仍在使用的堆对象变多。NextGC 上升,说明下一轮 GC 目标被抬高。NumGC 增长很快,说明 GC 频率高。HeapReleased 很低但 RSS 很高,可能说明 Go 还没把空闲页释放给操作系统,也可能是 Go 外内存占用。这里不能凭一个图下结论。
我更推荐把指标拆成三组看:
| |
存活规模决定“GC 能不能回收”。分配速度决定“GC 会不会频繁被触发”。GC 代价决定“它到底有没有影响业务”。这三件事混在一起看,最后一定会调歪。
还有一个很容易被忽略的细节:不要只在故障当天打开这些指标。
GC 问题最怕没有基线。你不知道正常高峰期 NumGC 每分钟涨多少,不知道健康状态下 /gc/heap/live 是 300MiB 还是 900MiB,也不知道一次发布之后分配速率是不是悄悄翻倍。等到 p99 抖起来再看,所有数字都像嫌疑人。
更稳的做法,是把 GC 指标当成服务体检项,而不是事故现场才拿出来的工具。每次大版本发布后,看一眼 live heap、alloc rate、GC CPU、RSS 峰值有没有阶跃变化。很多 GC 调优根本不需要等线上报警,发布当天就能发现苗头。
如果某个版本业务 QPS 没变,/gc/heap/allocs:bytes 却明显抬头,先别急着调 GOGC。那多半是代码引入了新的临时对象。参数能帮你拖一阵,代码才是源头。
四种常见配置,不要照抄
很多团队喜欢问“线上 Go 服务推荐 GOGC 多少”。这个问题本身就不太对。
参数不是模板,是交易条件。
如果你非要有一个起点,可以按场景拆。
第一种,普通 API 服务,内存不紧,GC CPU 偶尔上来。先不动 GOMEMLIMIT,保持 GOGC=100,把指标接好。如果确认 GC 周期和 p99 抖动重合,再试 GOGC=150。不要一步到 300。
| |
第二种,容器内存紧,RSS 高峰已经靠近 limit。先别提高 GOGC。更稳的做法是设置 GOMEMLIMIT,同时保留余量。
| |
如果 2GiB 容器里还有 sidecar、cgo、mmap 或大文件缓存,1500MiB 都未必保守。你要看实际 RSS,而不是只看 heap。
第三种,高频短命对象。比如网关、日志清洗、协议编解码、JSON 重度服务。这类服务里,提高 GOGC 可能短期降低 GC 次数,但更重要的是减分配。
| |
这类问题不是“把 GC 调服”,而是别再给 GC 塞垃圾。
第四种,批处理或短生命周期任务。有人会想直接 GOGC=off。这不是完全不能做,但条件很苛刻:进程生命周期短、数据规模可控、内存峰值压测过、失败代价可接受。长跑服务不要把关闭 GC 当优化技巧。
| |
如果这个 job 可能因为输入变大跑很久,或者跑在容器里,至少要配合 GOMEMLIMIT,并且压测峰值。否则吞吐是好看了,死得也干脆。
什么时候应该停手
GC 调优最容易上瘾。
从 100 到 150,有一点收益;从 150 到 200,又有一点收益;再往上,好像还能挤。问题是每一步都在扩大内存峰值和尾部风险。
所以调参前要写停手条件。
比如:
| |
如果只满足第一条,不算成功。很多“优化成功”的事故,都是只看 CPU 图做出的。
反过来,如果调完 GOMEMLIMIT 后 GC CPU 上升,也不一定是坏事。它可能是在用更多 CPU 换更稳的内存边界。只要 p99、吞吐和错误率能接受,这笔交易就可能是划算的。
真正的问题不是 GC CPU 从 2% 变成 4%。真正的问题是你不知道这 2% 买来了什么。
一份可以直接照着查的现场清单
遇到“GC 可能导致延迟抖动”时,我会按这个顺序问:
| |
这十个问题问完,通常就不会再出现“先把 GOGC 调大试试”的冲动。
因为你已经知道,自己到底在调什么。
一个更稳的线上调参方式
假设现在的状态是:GC CPU 5%,p99 周期性抖,容器 2GiB limit,RSS 高峰 1.2GiB,live heap 稳定在 600MiB 左右。
这种情况下,可以小步试:
| |
先不要一步到 300,也不要直接关 GC。观察一个完整高峰。如果 GC CPU 降了,p99 抖动缓解,RSS 仍然远离 limit,可以继续评估 GOGC=200。
如果 RSS 很快顶上去,回滚。
另一种情况:容器 2GiB limit,RSS 高峰已经 1.8GiB,偶发 OOMKilled,GC CPU 只有 2%。这时调高 GOGC 基本是在作死。更合理的是先给 runtime 边界:
| |
然后再看是不是需要降低分配、缩小缓存窗口、拆批处理、复用大 buffer。
还有一种情况:p99 抖,但 allocs/op 很低,gctrace 稀疏,GC CPU 也不高。别硬往 GC 上靠。去看锁、网络、数据库、调度、系统调用。
调优最怕的是先有答案,再找证据。
结尾:别把参数当止痛药
回到开头那个场景。
GC CPU 5%,p99 周期性抖,到底要不要调 GOGC?答案不是“要”或“不要”,而是先把账拆开。
如果是 CPU 在付账,内存还有空间,可以让 GC 晚一点来。如果是内存在付账,容器快顶不住了,就先给 GOMEMLIMIT 画边界。如果 live heap 一直涨,别怪 GC,它只是看见对象还活着。如果短命对象太多,调参数只是让账单晚一点到。
Go GC 已经把很多事情做得足够好了。真正容易出问题的,不是 runtime 不聪明,而是我们把不同问题都塞给一个参数。
GC 调优不是找神奇数字。
是把证据摆出来,然后决定:这次到底该省 CPU,还是该省内存。