Go GMP 里最容易背错的不是 G 和 M,而是 P
很多人能背出 G 是 goroutine、M 是线程、P 是 processor,却讲不清 P 为什么存在。理解 Go 调度器,关键不是记住三个字母,而是看懂 runtime 为什么要把任务、线程和执行资源拆开。
很多人聊 Go 调度器,开口就能背:G 是 goroutine,M 是 machine,P 是 processor。
背完以后,问题来了:为什么已经有 M 这个 OS 线程,还要多一个 P?
如果这个问题答不上来,GMP 其实还没真的理解。你只是记住了三个缩写,没有看懂 Go runtime 真正在拆哪几件事。
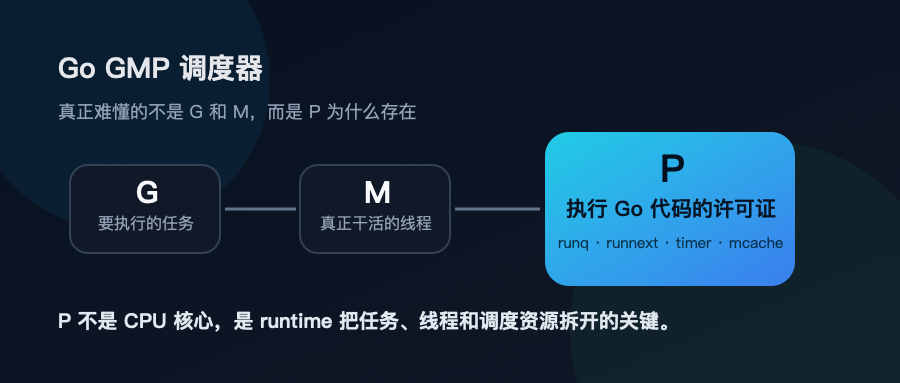
P 最容易被讲错。有人把它说成 CPU 核心,有人把它说成调度器,有人干脆把它当成 G 和 M 之间的中间层。都不够准。
更贴近源码的说法是:P 是执行 Go 代码所必须持有的 runtime 资源。
它不是硬件 CPU 核心,而是 Go runtime 给 M 发的一张“执行许可证”。M 拿到 P,才能运行 Go 代码;M 没有 P,可以阻塞在 syscall 里,可以停着,可以等着,但不能继续执行普通 Go goroutine。
这就是 GMP 设计里最关键的一刀。
它把“任务”“线程”“执行资源”拆开了。
G 不是线程,是一份可被调度的任务
先看 G。
G 很容易被叫成“轻量级线程”。这个说法方便,但也容易让人误会:好像 go f() 就是开了一个便宜点的线程。
实际不是。
go f() 创建的是一个 goroutine 对应的 G。G 里有自己的栈边界、调度上下文、状态、当前绑定的 M,以及一些抢占相关的标记。它代表的是“这段 Go 代码以后要被某个 M 执行”。
重点在“以后”和“某个”。
创建 G 不等于马上有一条 OS 线程跟它一一绑定。它会先进入调度队列,等某个持有 P 的 M 把它取出来,切到它的上下文上运行。
所以 goroutine 便宜,不是因为线程突然变便宜了,而是因为 Go 没有为每个 goroutine 固定创建一条线程。大量 G 被放在 runtime 自己的调度体系里,由少量 M 轮流执行。
这个差别很重要。
如果把 G 误解成线程,就很难解释为什么几十万 goroutine 可以存在;也很难解释一个 goroutine 阻塞以后,为什么不一定拖死整个程序。
G 是任务,不是工人。
任务可以排队,可以暂停,可以被重新唤醒,可以被回收。真正干活的是 M。
M 是 OS 线程,但它不是调度的全部
M 对应 OS thread,也就是 runtime 里的 worker thread。
从操作系统视角看,真正拿 CPU 时间片的是线程。Go 代码最终也必须跑在某条 OS 线程上。M 就是这条线。
但只说 M 是线程,还是不够。
Go runtime 里有很多调度逻辑并不在用户 goroutine 的栈上跑,而是在 M 的 g0 栈上跑。M 要找下一个可运行的 G,要切换上下文,要处理一些 runtime 路径,这些都需要一个“调度栈”。这也是为什么源码里经常能看到从用户 G 切到 g0,再执行调度函数。
M 持有当前正在运行的 G,也可能处于 spinning 状态去找活,还可能因为系统调用卡在内核里。
这里会出现一个麻烦:如果 M 进了阻塞 syscall,它所在的 OS 线程卡住了。那跟它关联的执行资源怎么办?
早期只看 G 和 M,问题会变得很难受。线程阻塞了,调度资源也容易跟着被占住。全局队列、全局锁、线程唤醒都会变成瓶颈。
P 的存在,就是为了解开这个结。
P 不是 CPU 核心,是执行 Go 代码的资格
很多 GMP 文章最危险的一句话是:P 代表 CPU 核心。
这句话能帮初学者建立一点直觉,但正式理解时必须扔掉。
P 不是物理核心。P 的数量由 GOMAXPROCS 控制,现代 Go 默认通常会按可用 CPU 并行度设置,但它仍然是 runtime 里的抽象,不是硬件本身。
你可以把 P 想成一个工位和工具箱。
M 是干活的人,G 是活,P 是工位和工具箱。没有工位,工人站在那里也不能炒 Go 代码这盘菜。
这个“工具箱”里有什么?
在 Go 1.25.4 的 runtime 实现里,P 上承载了本地 run queue、runnext、timer、mcache、GC worker 状态、write barrier buffer 等一批 per-P 资源。
也就是说,P 不只是一个计数器。它把很多原本容易挤到全局锁上的东西局部化了。
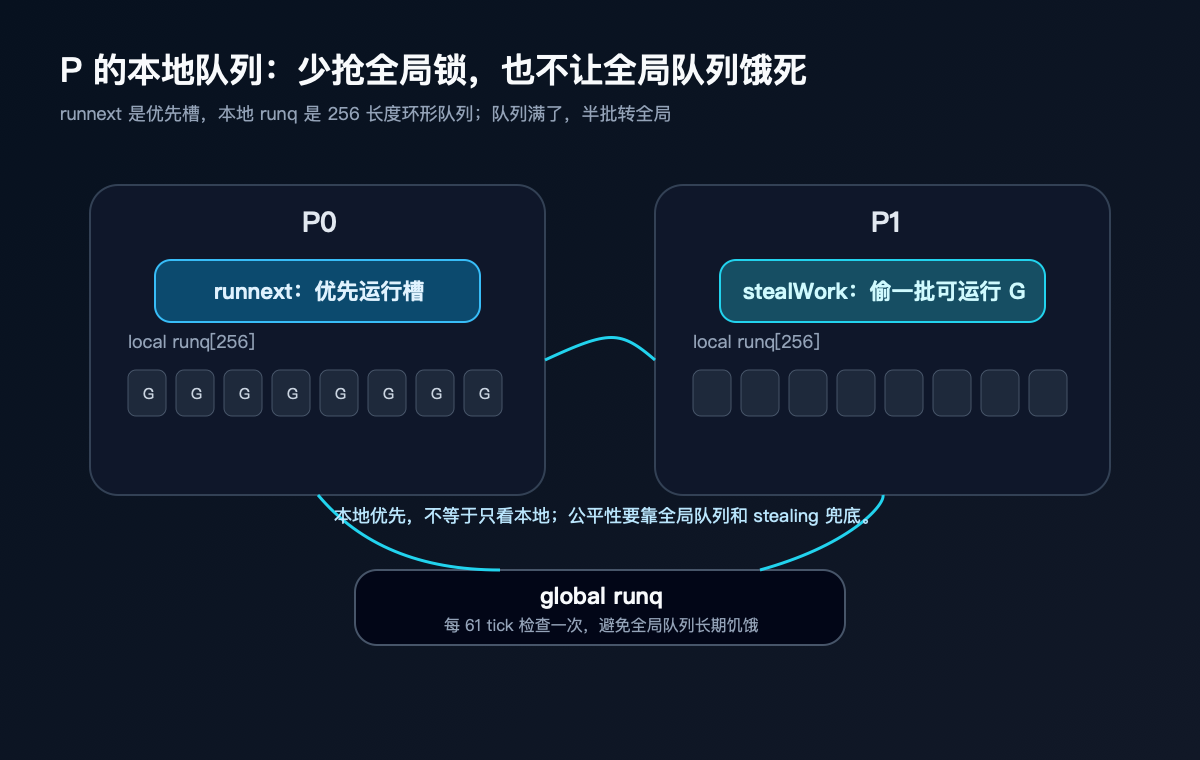
本地队列是其中最直观的一项。
每个 P 有自己的本地 runq,当前实现中是 256 长度的环形队列,还有一个 runnext 优先槽。新变成 runnable 的 G,很多时候会优先放到当前 P 的本地队列里,而不是每次都去抢全局队列。
这能减少什么?
减少全局锁竞争,也提高局部性。一个 M 持有 P,在这个 P 的本地队列里连续取 G 执行,不需要所有线程都围着一个全局队列抢。
但本地优先不等于本地独占。
如果本地队列满了,runqputslow 会把一部分 G 批量转到全局队列。findRunnable 也会定期检查全局队列,避免全局队列里的 G 长时间饿死。空闲的 M 还会通过 work stealing 从别的 P 偷一批 runnable G 或 timer work。
P 这层抽象,把调度从“所有线程抢一口锅”变成了“每个工位有自己的待办,忙闲之间再互相均衡”。
这才是 P 值钱的地方。
还有一个判断可以帮你避免把 P 讲歪:看一项资源到底应该跟“线程”走,还是应该跟“执行 Go 代码的资格”走。
比如内存分配缓存。
如果每次小对象分配都去抢全局结构,goroutine 再轻也扛不住高频分配。Go 把 mcache 放在 P 上,就是因为它更像“当前执行单元的局部工具”,而不是某条 OS 线程的私人物品。M 拿到哪个 P,就使用哪个 P 上的局部缓存。M 失去 P,也就失去继续执行 Go 代码和使用这些 per-P 资源的资格。
timer 也是同一类直觉。
一个 P 上有自己的 timer heap,调度器在找活时也会考虑 timer。你不需要把每个 timer 都想成全局大钟上的一条记录。很多 runtime 工作被压到 per-P 层面,目的都是一样的:把全局竞争拆散,让大多数调度决定在局部完成。
GC worker 状态更能说明问题。
并发 GC 不是完全脱离用户 goroutine 的另一个世界。GC 也要吃 CPU,也要被安排执行。P 上保存 GC worker 相关状态,意味着 runtime 在分配 P 的执行权时,也在分配一部分 GC 工作的机会。业务代码、GC、timer、netpoll 都不是孤岛,它们最后都要回到“谁持有 P,谁可以推进 Go 世界”这件事上。
所以 P 的核心不是名字里的 processor,而是边界。
有了 P,Go runtime 才能把这些局部资源放在一个比线程更合适的位置:线程可以换,任务可以换,但执行 Go 代码这件事需要一套稳定的本地资源。
一个 go f() 到底怎么跑起来
把概念放回一条路径,会清楚很多。
当你写:
| |
runtime 并不是给 f 开一条新线程。大体路径是:创建一个新的 G,初始化它的栈和调度上下文,把用户函数返回后的出口接到 goexit,然后把这个 G 放进可运行队列。
如果当前 P 的 runnext 可用,runtime 可能会把它放进这个优先槽;否则放入本地 runq。队列满了,就把一批 G 转到全局 runq。
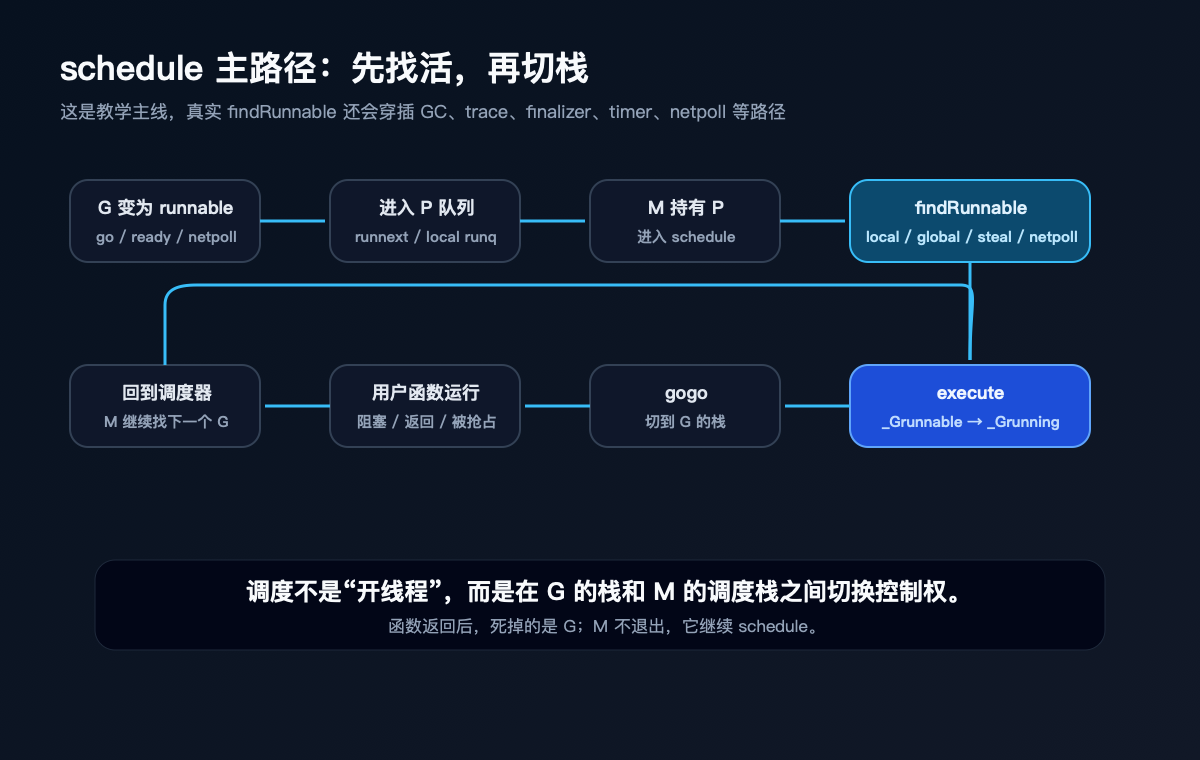
另一边,一个 M 持有 P,进入 schedule。
schedule 的职责可以先简单理解为:找一个 runnable G,然后执行它。
真正找活的是 findRunnable。它不是机械地按“本地队列 → 全局队列 → 偷取”三步走完。Go 1.25.4 里的路径比这复杂,会穿插 GC worker、trace reader、finalizer、timer、netpoll、work stealing、idle GC 等逻辑。
但为了建立主线,可以先这样看:
- 先处理一些 runtime 必须优先看的工作,比如 GC 相关路径。
- 每隔一定调度 tick 检查全局队列,避免全局 G 饥饿。
- 从当前 P 的
runnext或本地 runq 取 G。 - 必要时从全局队列取一批。
- 看看 netpoll 有没有已经就绪的网络 G。
- 还没有,就尝试从其他 P steal work。
- 再没有,M 可能释放 P,进入阻塞 netpoll 或 stopm。
找到 G 以后,进入 execute。
execute 会把 G 的状态从 _Grunnable 改成 _Grunning,把 M.curg 指向这个 G,把 G.m 指向这个 M,然后通过 gogo(&gp.sched) 切到 G 保存的上下文上。
这里有一个很容易被忽略的点:调度不是函数调用意义上的“继续往下走”。它是在调度栈和 goroutine 栈之间切控制权。
所以源码里说 execute never returns,不是说这个 M 永远回不来,而是说控制权切到另一个栈上了。等这个 G 阻塞、被抢占或者函数返回,控制权会通过别的路径再回到调度器。
函数返回时,goroutine 不是“返回给创建它的人”。它会走到 goexit,进入 goexit1、goexit0,最后 gdestroy 把 G 清理并回收到 free G 缓存里。
然后 M 怎么办?
M 不死。它继续回到 schedule,找下一个 G。
goroutine 结束时,死掉的是 G,不是 M。
这一点一旦想通,很多 Go 并发现象就没那么神秘了。
这里还要补一层:为什么 schedule 通常运行在 g0 上?
用户 goroutine 的栈是给用户函数用的。调度器不能总在用户栈上做复杂操作,否则切换、扩栈、抢占、状态转换会互相缠住。M 有自己的 g0,runtime 调度逻辑可以切到 g0 栈上运行。等找到下一个 G,再通过保存好的调度上下文切过去。
这就是很多人看源码时最不适应的地方:你以为自己在追一个普通函数调用链,其实已经在追不同栈之间的控制权交接。
mcall、gogo、goexit 这些名字看起来很底层,但心智模型可以简单一点:
- 用户 G 要让出执行权时,控制权回到 M 的 g0 栈。
- 调度器在 g0 上找下一个可运行 G。
- 找到后,再切到那个 G 的栈继续跑。
所以不要把 Go 调度器想成一个纯粹的数据结构问题。队列当然重要,但真正发生的是栈、状态和执行权一起切换。
如果你读 schedtrace,也可以按这个心智模型看。
schedtrace 一屏输出里会出现 P、M、G 的状态统计。新手最容易陷进去的是逐字段硬啃。更好的读法是先问三件事:现在有多少 P 能执行 Go 代码?有多少 M 在跑、在等、在 syscall?大量 G 是 runnable,还是 waiting?
如果 runnable G 很多,但可用 P 很少,瓶颈可能不是 goroutine 不够,而是并行执行权不够。如果 M 很多但大多在 syscall 或等待,说明线程数量和可执行 Go 代码的数量不是一回事。P 才是把这两件事连接起来的那个层次。
runnext、本地队列和 work stealing
P 的本地队列,是理解 GMP 性能直觉的关键。
如果所有新 G 都扔到一个全局队列里,每次调度都要抢一把全局锁,那 goroutine 再轻也会被全局竞争拖住。P 的本地 runq 让大多数调度先在局部完成。
runnext 则更像一个插队槽。
某些当前 G ready 出来的 G,会被放到 runnext,下一次 runqget 优先取它。这样能让紧密相关的 goroutine 更快接上,减少没必要的延迟。
但它不是无限特权。
runnext 继承当前时间片,runtime 也会防止某些 ping-pong goroutine 长期霸占执行机会。源码注释里也能看到,其他 P 在 stealing 的最后阶段可能尝试处理 runnext。正式写文章时,不能把它说成“绝对不可偷的私有槽”。
本地队列也会失衡。
有的 P 手里一堆 G,有的 P 空了。空闲 M 如果还能拿到 P,就不能一直傻等。它会尝试 work stealing,从其他 P 的 runq 或 timer work 里偷一批。
注意,是偷 G,不是偷线程。
stealing 的目的不是让 M 越来越多,而是让已经存在的执行资源别闲着。Go 调度器一直在做这个平衡:有活时尽量把 P 用起来,没活时别让线程无上限空转。
这也是 spinning M 的意义。
spinning M 像站在门口等单的骑手。它手上暂时没活,但还在主动看有没有活。这样新 G 出现时,不必每次都从睡眠线程开始叫醒,延迟会低一些。可如果每个没活的 M 都一直 spin,又会浪费 CPU。
所以 runtime 有一套很小心的 wakep/startm/stopm 逻辑:该叫醒时叫醒,该停就停,已有 spinning M 时通常不再唤醒更多线程。
这类细节看起来绕,本质还是同一个目标:让 P 尽量别闲着,同时别制造线程风暴。
syscall 卡住的是 M,不该顺手锁死 P
P 还有一个特别重要的价值:处理阻塞系统调用。
一个 goroutine 进入 syscall 时,实际卡住的是运行它的 M,也就是那条 OS 线程。这个 G 还在那个 M 上等系统调用返回,不能突然被别的 M 继续执行。
但 P 不应该一起陪葬。
如果 M 进入 syscall,runtime 会把 M 和 P 脱开。M 记录 oldp,G 进入 _Gsyscall,P 进入 _Psyscall。如果这个 syscall 阻塞较久,P 可以被 handoff 或 retake 给其他 M,用来继续执行别的 G。
这句话要特别小心:不是 syscall 中的 G 被交给其他 M 跑了。
G 还在原来的 M 那里卡着。被释放出来的是 P,也就是执行其他 Go 代码所需的那份 runtime 资源。
等 syscall 返回,M 会先尝试拿回 oldp。如果 oldp 还在,就快速恢复执行。如果拿不回,就尝试拿其他 idle P。再不行,这个 G 会被放回全局 runq,等待之后被调度。
为什么要这么麻烦?
因为系统调用的阻塞时间不由 Go runtime 控制。线程可能被内核卡住。如果 P 也跟着卡住,等于明明还有其他 runnable G,却因为执行许可证被压在一个 syscall 里,整个程序的并行度被白白浪费。
P 的存在,让 Go 可以说:线程你先在内核里等,工位我拿出来给别人用。
这就是 syscall handoff 的直觉。
研究素材里的示例把 GOMAXPROCS 设成 1,一个 goroutine sleep,另一个 CPU goroutine 继续跑。它不是严格证明所有 syscall 细节的实验,time.Sleep 也主要走 runtime timer 路径;但它很适合帮你建立这个心智模型:阻塞一段逻辑,不应该等于浪费整个 P。
| |
如果你想观察调度器状态,可以配合 schedtrace:
| |
输出里的字段很多,不建议一上来逐个背。先看三个问题就够了:当前 gomaxprocs 是多少,有多少 P,M/G 大概处于什么状态。等主线稳了,再回头看细字段。
抢占、GC 和 netpoll:P 不只服务用户代码
到这里还只是主路径。真正的 Go 调度器还要和 GC、网络轮询、抢占协作。
比如 GC。
Go 的并发标记不是一个完全脱离调度器的神秘线程池。findRunnable 里会尝试安排 GC worker;没有普通用户 G 可跑时,也可能运行 idle-time marking。P 上也保存着 GC worker mode、GC work buffer、write barrier buffer 等状态。
这说明 P 不只是“跑你的业务 goroutine”。它也是 runtime 在用户代码、GC 工作、timer、netpoll 之间分配执行机会的载体。
再比如 netpoller。
网络 fd 就绪时,netpoller 不会直接回调你的业务函数。它做的是把等待 fd 的 G 变回 runnable list,然后仍然交给调度器。最终还是要有 M 持有 P,把这个 G 找出来执行。
再看抢占。
Go 1.14 之后,goroutine 支持 asynchronous preemption。没有函数调用的紧循环,不再像早期那样容易拖住调度器或明显延迟 GC。
但这不等于 Go 变成了“任意机器指令都能实时抢占”。当前实现里仍然有 safe-point 条件:必须是合适的 user G、M/P 状态允许、栈空间足够、PC 在 Go code,且不能处在 runtime 标记的不安全点等。
所以写 Go 调度器时,最忌讳把源码里的复杂条件压成一句绝对判断。
调度顺序不是 Go 语言规范保证。本文讲的是 Go 1.25.4 runtime 当前实现下适合建立心智模型的主线。未来版本可以调整细节,平台也会影响 netpoll 和信号机制。
理解这一点,反而更不容易被八股带偏。
GOMAXPROCS 控制的是 P,不是 goroutine 数量
再回到一个最常见的问题:GOMAXPROCS 到底控制什么?
它控制的是同时执行 Go 代码的 P 数量,也就控制了 Go runtime 层面的并行执行权数量。它不控制 goroutine 能创建多少个,也不直接等于 OS 线程总数。
可以用一个很小的实验感受它。
| |
在本机 Go 1.25.4、8 核环境里,研究示例跑出来的趋势很直接:GOMAXPROCS=1 最慢,GOMAXPROCS=2 明显变快,GOMAXPROCS=8 更快。
但这组数字不能当成通用 benchmark。不同机器、温控、后台负载、容器 CPU quota 都会影响结果。
它真正能说明的是:CPU 密集型 goroutine 能不能并行推进,关键看有多少 P 能同时执行 Go 代码。
goroutine 可以很多,P 是有限的。
这也是 Go 并发模型里很容易被忽略的一点:并发不是并行。你可以创建大量 G,让它们在等待、运行、唤醒之间切换;但同一时刻真正执行 Go 代码的数量,受 P 限制。
历史上看,P 也不是一开始就天然存在的答案。
早期 Go 调度器可以粗略理解为 G 和 M 的模型。这个说法只是背景概括,不能把今天的实现硬套回 Go 1.0。真正值得记住的是,Go 1.1 的调度器设计让 P 成为关键抽象:把执行资源从线程里拆出来,把本地队列、调度状态、内存分配缓存等放到 per-P 层面。
Go 1.5 又让这个设计变得更重要。runtime/compiler Go 化,并发 GC 进入主线,默认 GOMAXPROCS 改为 CPU 核数。调度器不再只是“让 goroutine 轮流跑”的工具,它还要给并发 GC 留出执行机会。
Go 1.14 的异步抢占,则是在另一个方向上补洞:以前没有函数调用的紧循环更容易拖住调度器和 GC,现在 runtime 可以用更主动的方式打断它。但这依然不是实时系统式的任意点抢占。
这段演进说明一件事:GMP 不是为了面试题长出来的。
它是在解决真实工程矛盾:多核要用起来,线程数量不能失控,GC 要能推进,syscall 不能浪费执行权,网络 IO 就绪后要能回到调度队列。
如果只把 GMP 背成三个名词,就看不到这些矛盾。
为什么 GMP 要拆成三件事
现在可以回答开头的问题了:为什么已经有 M,还要有 P?
因为 M 是 OS 线程,线程不适合同时承载所有调度资源。
如果把任务、线程、队列、缓存、timer、GC 状态都绑在一起,线程一阻塞,资源就容易跟着浪费;所有工作都堆到全局,又会带来锁竞争;线程唤醒太保守,延迟高,太激进,又浪费 CPU。
GMP 的设计,是把三件事拆开:
- G:要执行的任务。
- M:真正运行代码的 OS 线程。
- P:执行 Go 代码所需的 runtime 资源和并行执行权。
拆开以后,runtime 才有空间做这些事:
- G 可以大量存在,不和 OS 线程一一绑定。
- M 可以阻塞在 syscall 里,而 P 被释放给别的 M。
- P 可以拥有本地 runq,减少全局竞争。
- 空闲 M 可以 work stealing,平衡不同 P 的负载。
- GC worker、timer、netpoll、抢占都能嵌入调度路径。
这套设计当然有代价。
代价是复杂。你不能只看用户代码,还要看 runtime 怎么在不同栈之间切换;不能只看一个队列,还要看本地、全局、stealing、netpoll;不能把调度顺序当成语言保证,只能说某个版本的当前实现大体如此。
但收益也很明确:Go 用这层 runtime 调度,把大量 goroutine 放进一个可控的执行系统里,而不是把问题全部丢给 OS 线程。
所以学 GMP,不要停在“G 是 goroutine,M 是线程,P 是 processor”。
这句话只够当目录,不够当理解。
真正要记住的是:
P 不是 CPU 核心,是 Go runtime 的执行许可证。
这句话比“G 是 goroutine、M 是线程、P 是 processor”更值得记。因为它能解释后面所有问题:为什么本地队列要挂在 P 上,为什么 syscall 要释放 P,为什么 GOMAXPROCS 限制的是并行执行权,为什么 GC worker 也会进入调度路径。
等你再看到 schedule、findRunnable、execute、handoffp 这些函数名时,就不会只是在源码里迷路。你会知道它们都在围着同一件事转:别浪费 P,也别让 P 被错误地绑死。
看懂 P,GMP 才从三个字母变成一个调度系统。
后面再谈 netpoll、抢占、GC assist、sysmon retake,才不会变成一堆散落的 runtime 术语。你也能分清哪些是语言层面的承诺,哪些只是当前 runtime 为了效率做出的工程选择。这种边界感,比多背几个函数名更重要,也更耐用一点。