pprof 数据到底怎么用:Go 为什么要沿三条线把 goroutine 泄漏钉回代码
pprof 只告诉你在哪,不告诉你为什么。按创建路径、取消路径、响应路径三条线,把每个阻塞 goroutine 的生命周期拆清楚——是谁创建的、谁来取消、有没有响应 Done。
pprof 抓回来了,最容易发生的事不是你看不懂。
而是你看懂了一半:知道一批 goroutine 卡在 main.worker,知道等待状态是 [chan receive],知道创建点也在栈里,可下一步还是开始全局搜 context、搜 worker、搜 channel。
这一步如果走散了,pprof 就只是一张截图。
真正的排查,不是把 profile 看完,而是把 profile 里的线索钉回代码里。
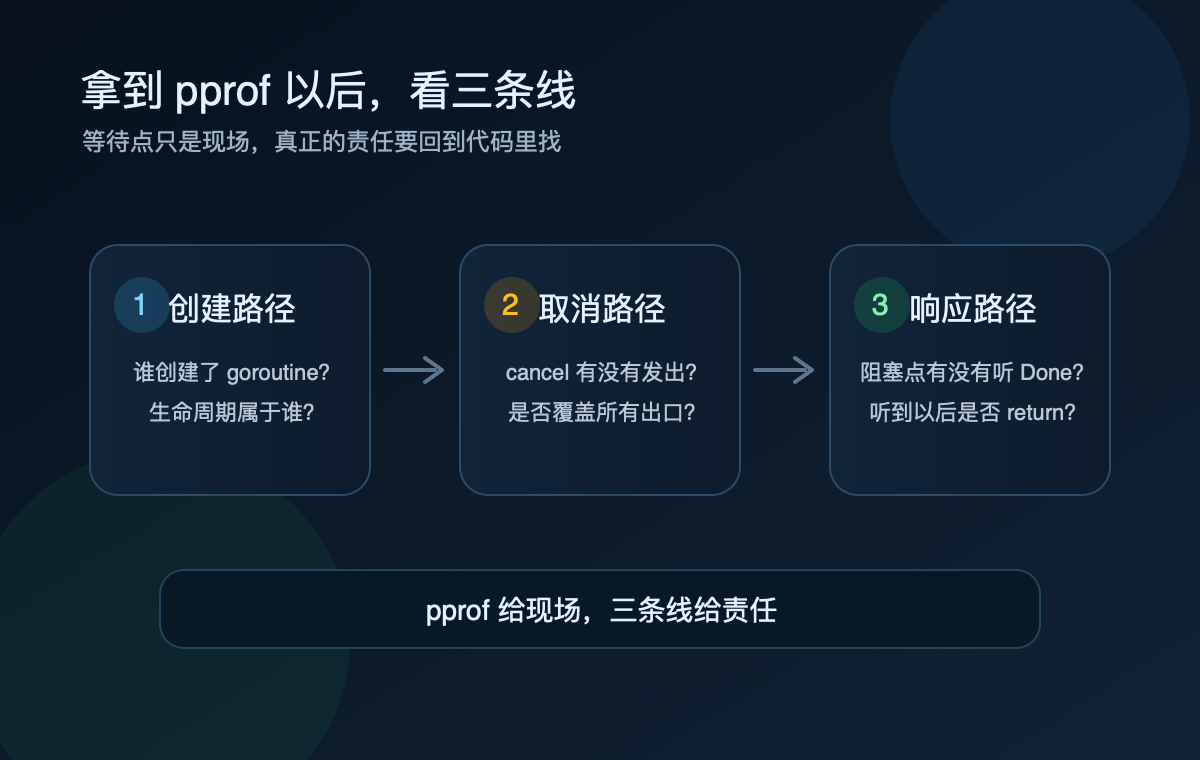
上篇讲到这里:goroutine 数先采样,再用 pprof 把“数量”变成“栈”。这篇接着往下走。
拿到栈以后,不要急着改。
先问三条线:
| |
这三句话,比“是不是 context 泄漏”更有用。
因为 context 从来不是强杀按钮。它只负责发出取消信号。goroutine 会不会退,取决于这条信号有没有被创建、有没有被触发、有没有被听见。
pprof 只告诉你 goroutine 停在哪,不会告诉你谁该负责让它停下。
实际排查时,可以把 pprof 输出先拆成三栏:
| |
前两栏通常能从 profile 里找到。
第三栏不在 profile 里,它在代码设计里。
这也是很多人卡住的地方:工具已经把现场给你了,但工具不会替你理解业务生命周期。一个消费消息的 goroutine,应该跟着进程活;一个处理请求的 goroutine,应该跟着请求结束;一个临时 fan-out 出去的 goroutine,应该跟着这一轮任务收口。生命周期不同,修法完全不同。
同样是 [chan receive],如果它是常驻消费者,可能是正常等待;如果它是请求里临时启动的 worker,压测停了还挂着,就很可疑。
所以不要把等待状态直接翻译成根因。
等待状态只是现场照片。三条线才是证词。
我更建议把这一步写成一张很短的排查记录,而不是在群里丢一段 profile 截图:
| |
记录一旦这么写,讨论就会从“是不是 channel 的锅”变成“这个 goroutine 到底归谁管”。这才是 pprof 真正开始有用的地方。
第一条线:创建路径,先找生命周期归谁
先从 pprof 给出的创建点往回看。
典型的栈里会有这类信息:
| |
这两段信息要分开读。
main.worker 那一行告诉你:它现在停在哪里。
created by main.main 那一行告诉你:它从哪里被放出来。
很多人只看阻塞点,不看创建点。结果就会在 worker 里面打转:是不是 channel 没关?是不是 select 写错?是不是有人没发送?
这些都要查,但还不够。
你还要回到创建处,看这个 goroutine 本来应该属于谁。
| |
这里至少要问四个问题:
- 这个
parent是请求级、任务级,还是进程级? worker的生命周期是否应该跟着这个ctx结束?- 创建 goroutine 的地方,是否也是负责取消它的地方?
- 如果不是,取消责任被交给了谁?
很多泄漏不是因为代码里没有 ctx。
恰恰相反,代码里到处都是 ctx,但生命周期没人负责。请求级 context 被塞进后台队列,任务级 context 又从 Background() 派生,业务函数层层传参,看起来很规范,实际上谁都没有权利结束它。
这里还有一个很现实的信号:如果你问“这个 goroutine 最晚什么时候必须退出”,团队里没人能立刻回答,那它迟早会变成排查成本。
写 goroutine 不是只写启动代码。启动只是半句,退出才是另外半句。
尤其是 fan-out、异步回调、消息消费、批处理任务这些地方,创建代码往往很顺手:go func() 一包,逻辑就跑起来了。可一旦上游请求取消、任务失败、队列关闭、服务准备退出,这个 goroutine 应该听谁的?如果代码没有表达出来,pprof 最后会替你把这笔账翻出来。
这时你看到的 pprof 现象,可能只是最后一环。
真正的问题在创建路径上。
泄漏常常不是没人写 context,而是没人拥有生命周期。
所以第一条线先别改代码,先画边界:这个 goroutine 为什么存在?它应该在什么事件发生后退出?谁有资格发出这个退出信号?
这三个问题答不上来,后面补多少 select 都容易补歪。
第二条线:取消路径,cancel 有没有覆盖所有出口
创建路径说清楚以后,再看取消路径。
Go 官方 context 文档对这件事说得很直接:调用 CancelFunc 会取消 child 和它的 children,移除 parent 对 child 的引用,并释放相关资源。WithTimeout 的例子里也明确写了 defer cancel(),哪怕操作提前完成,也要释放资源。
也就是说,cancel 不是装饰品。
它是生命周期的收口。
最常见的错误,是把它丢了。
| |
这段代码不一定会让 goroutine 立刻暴涨。
更准确地说,它会让 context 相关资源保留得更久:child context、timer、parent 对 child 的引用,都要等 deadline 到,或者等 parent 被取消。请求量小的时候,你可能看不出什么;请求量一大,一分钟就足够堆出一片阴影。
go vet 能抓住这类问题。
| |
它会报得很直白:
| |
修复也不复杂:
| |
但这里有两个坑。
第一个坑:defer cancel() 写晚了。
| |
看起来写了 defer cancel(),但 check() 提前返回时根本走不到。更稳的写法,是创建之后立刻安排释放。
| |
第二个坑:循环里无脑 defer。
| |
如果循环很多次,所有 cancel 都拖到外层函数退出才执行。资源不是没释放,是释放得太晚。
可以包一层小函数:
| |
也可以在本轮结束后显式调用:
| |
重点不是背哪一种写法。
重点是所有成功、失败、提前返回路径,都要能走到 cancel()。
go vet 在这里很有价值,但别把它当成万能侦探。
它能抓“你把 cancel 丢了”。它抓不住“goroutine 收到了 ctx,却完全不理 Done()”。
所以第二条线查完,只能说明取消信号有没有被发出。
信号发出以后有没有人听,是第三条线。
第三条线:响应路径,阻塞点有没有听 Done
这是最容易被误判的一类泄漏。
看这段代码:
| |
cancel() 调了。
但 worker 完全不知道这件事。它没有接收 ctx,也没有监听 ctx.Done()。它只是在等 channel。
如果永远没人发送,或者 channel 永远不关闭,它就永远挂在那里。
这就是为什么 pprof 里会看到:
| |
这时你不能只问“cancel 有没有调”。
你要问的是:这个阻塞点有没有退出协议?
修复通常是把 ctx.Done() 放进同一个 select:
| |
如果 worker 是循环,更要小心。
| |
这里要用 return,不要随手写一个 break。
| |
这段代码的问题很隐蔽:break 只跳出了 select,外层 for 还在继续。你以为 worker 退出了,它其实只是原地转了一圈。
这类 bug 在 review 时很容易漏,因为代码看起来已经“监听了 Done”。
但排查泄漏不能只看有没有监听。
要看监听后是否真的退出。
还有一类更隐蔽:监听了 ctx.Done(),但真正耗时的操作没有接收同一个 ctx。
| |
这段代码表面上看过 Done(),实际远程调用用的是新的 Background()。上层超时了,下层照样等。pprof 里你可能看到 [IO wait],日志里你可能看到请求已经取消,但 goroutine 迟迟不退。
这种问题不能靠“有没有 ctx 参数”判断。
要沿着调用链追到底:阻塞的那个调用,到底用的是不是同一个生命周期。
所以响应路径的检查要更硬一点:
| |
Done 被写进 select,不等于 goroutine 会退出。退出路径必须真的走到 return。
两个场景,优先从这里下手
把三条线放到真实排查里,最常见就是两种场景。
场景一:cancel 被丢弃
特征是 go vet 能先报出来,或者你在代码里看到 WithCancel、WithTimeout、WithDeadline 的返回值被忽略。
错误写法:
| |
或者更隐蔽一点:
| |
排查顺序很简单:
| |
这里要说得准一点:忘记 cancel 不一定等于 goroutine 泄漏。
如果没有 goroutine 在等这个 context,表现可能更多是 timer、child context、引用链保留得更久。如果同时有 goroutine 等着这条取消信号,那就可能变成 goroutine 不退。
所以正文、review、事故复盘里都不要写成“忘记 cancel 一定导致 goroutine 泄漏”。
更准确的说法是:忘记 cancel 会让 context 相关资源释放变晚,并可能放大 goroutine 退出问题。
场景二:goroutine 不监听 Done
这个场景 pprof 更明显。
你会看到一批 goroutine 卡在同一个业务函数上,等待状态可能是 [chan receive]、[select]、[IO wait],或者别的阻塞点。
这时三条线里的重点是响应路径。
不是问项目里有没有 ctx。
而是问卡住的那个阻塞点,有没有把 ctx.Done() 放进同一个等待结构里。
错误写法:
| |
修复:
| |
如果是网络调用、外部依赖、消息消费,逻辑也一样。
你要看超时和取消有没有真的传到最底层调用。上层创建了 timeout,但下层偷偷用了 context.Background(),等于把退出协议剪断了。
这种代码尤其危险,因为日志里看起来每层都在传 ctx,实际关键调用没有用同一个生命周期。
修完以后,看趋势,不要只看测试
泄漏类问题,修完不能只说“单测过了”。
你要回到最开始的证据链,看它有没有回落。
最小验证可以这样做:
| |
然后看三件事:
runtime.NumGoroutine()是否在压力结束后回落;debug=1里同一业务栈的数量是否下降;debug=2里是否还存在同一批等待状态。
如果怀疑是 WithTimeout、WithValue 或引用链保留带来的内存问题,还要补 heap profile:
| |
heap profile 受 GC 和采样影响,不要拿一次数字当判决。更稳的做法,是在同一复现场景下对比修复前后趋势。
这里也别忘了保留证据。
修复前 profile、修复后 profile、压测窗口、代码 diff,最好放在同一张排查记录里。以后团队再遇到类似问题,不用靠某个人回忆“上次好像是 channel 没关”。
如果团队里已经有 runbook,我建议把这几项固定进去:
| |
这不是为了写事故报告好看。
是为了下一次排查时,团队不用重新发明流程。
很多线上问题最耗时间的不是修复,而是前两小时大家各查各的:有人看日志,有人搜代码,有人猜下游,有人重启服务。最后可能都做对了一部分,但证据链没串起来。
三条线的价值就在这里。
它把讨论从“我觉得可能是某个 goroutine 没退”,拉回到“创建点在哪,取消点在哪,响应点在哪”。
这句话一问出来,很多争论会少一半。
最后,把三条线写进 review
这套方法不应该只在事故时用。
平时 review 涉及 goroutine、context、channel、外部调用的代码,就可以直接问这几个问题:
| |
上篇讲的是:goroutine 涨了,第一步别猜,先采样。
这篇要补上后半句:拿到 pprof,也别停在 pprof。
pprof 只是把你带到现场。
创建路径告诉你谁把 goroutine 放出来。
取消路径告诉你退出信号有没有发出去。
响应路径告诉你它有没有听见,并且真的离开。
以后再看到 goroutine 涨,不要从“是不是 context 泄漏”开始。
从三条线开始。
把泄漏从 profile 里拽出来,钉回代码里。
如果你正在排查 Go 服务里的 goroutine、context、channel 或 pprof 问题,可以关注我。后面会继续把这些线上排查方法拆成能直接拿去用的工程清单。