Go 1.25 的 map 已经换了一套发动机:Swiss Table 到底改了什么
很多 Go map 文章还在讲 hmap、bmap、overflow bucket 和 load factor 6.5。但从 Go 1.24 开始,默认 map 实现已经换成 Swiss Table。API 没变,底层发动机变了。
你读过的很多 Go map 文章,可能已经过时了。
它们还在讲 hmap、bmap、overflow bucket、load factor 6.5,还会画一张 bucket 后面挂着 overflow bucket 的图。那些内容不是没有价值。问题在于,从 Go 1.24 开始,默认 map 实现已经换成 Swiss Table;到了 Go 1.25,再把旧模型当成主线讲,就会把读者带偏。
map 的 API 没变。make(map[K]V) 还是那个写法,m[k] 还是查找,delete(m, k) 还是删除,range m 还是遍历。
但发动机已经换了。
旧模型里,map 更像一排 bucket,每个 bucket 装几个 key/value,冲突多了就挂 overflow bucket。新模型里,Go map 的核心变成了 Swiss Table:开放寻址、group、control word、H1/H2、多 table、extendible hashing。
这不是“源码爱好者才需要知道”的细节。你排查性能、解释内存占用、写技术分享,甚至只是判断某篇文章能不能信,都得先问一句:它讲的是 Go 1.24 以前的默认实现,还是现在的 Swiss map?

旧 hmap 没消失,但它已经不是默认主线
先把边界说清楚:旧的 hmap + bmap + overflow bucket 不是错。
它曾经是 Go map 的默认实现。今天在 Go 1.25.4 的源码里,旧实现也还在,文件名很直接:runtime/map_noswiss.go。问题是,它不再是默认路径。Go 1.24 的发布说明已经把 built-in map 的新 Swiss Table 实现作为默认行为;本机 Go 1.25.4 源码里,新的入口是 runtime/map_swiss.go,真正的核心实现则在 internal/runtime/maps 下面。
这就是很多旧文章现在最容易误导人的地方。
它们会告诉你:Go map 的 bucket 里有 8 个 cell,负载因子超过 6.5 触发扩容,冲突多了会有 overflow bucket。放在旧实现里,这套解释能讲通。但如果你把它当成 Go 1.25 的默认事实,就会出问题。
旧模型不是错,是不再默认。
更准确的写法应该是:Go 1.24 以后,默认 map 实现已经切到 Swiss Table;旧 bucket/overflow 仍可作为历史对照,或对应 noswissmap 旧实现,但不应该再拿来解释当前默认 map 的主路径。
这件事看似只是实现替换,实际影响很大。因为 map 的语言语义没变,很多人就误以为底层模型也没变。Go 恰恰是在这里做了一个很 Go 的选择:对使用者保持 API 稳定,对 runtime 内部继续换更适合 CPU 和内存层级的结构。
语言给你的是无序映射,runtime 负责把这件事越做越快。
Swiss Table 的关键,不是“更复杂”,而是先筛掉大多数不可能
Swiss Table 想解决的问题很朴素:查一个 key 时,别急着逐个比较完整 key。
完整 key 比较可能很贵。字符串要比内容,复杂类型还要走更重的 equality。哈希表真正希望的是:先用很便宜的方式,把“不可能是它”的位置排除掉,只留下少量候选。
Go 1.25.4 的源码注释说得很清楚:Swiss map 的基本单位是 group。一个 group 里有 8 个 slot,每个 slot 存一对 key/value;旁边还有一个 8 字节的 control word。control word 里的每个 byte 对应一个 slot,既记录这个 slot 是 empty、deleted 还是 used,也在 used 时存下这个 key 的 hash 低 7 位,也就是 H2。
查找时,Go 会把目标 key 算出来的 H2,拿去和这 8 个 control byte 做并行匹配。
不是直接比 8 个 key。
先比 8 个 7-bit hash 指纹。
如果 control word 里某几个 slot 的 H2 对上了,才继续做真正的 key equality。源码里还特别写了:只用 7 位 hash,每个 slot 误命中的概率大约是 1/128,但这没关系,因为最终还会做标准 key 比较。

这就是 Swiss Table 的味道:
一组 8 个 slot,不是让你一个一个傻找,而是用 control word 先做一次批量筛选。
它不靠魔法。它靠的是更贴近现代 CPU 的数据布局:少一点指针追踪,多一点连续内存;少一点完整 key 比较,多一点便宜的位运算筛选。
这也解释了为什么旧的 overflow bucket 模型不再适合作为默认心智图。overflow bucket 的问题不是“不能用”,而是冲突多了以后,查找路径会变成更多指针跳转。CPU 不喜欢这种跳来跳去的访问。Swiss Table 把更多信息压进连续 group 和 control word 里,让查找更像一段紧凑的扫描。
你可以把它想成一道门禁:旧模型更像沿着走廊一间间敲门;Swiss Table 是先看一眼门口的 8 个小标签,只有标签像的人,才真的开门核身份。
旧 bucket 是链出去,Swiss 是探下去
拿旧模型和 Swiss Table 对比,最重要的差别不是“一个新一个旧”,而是冲突处理的方向变了。
旧 hmap 的核心画法是 bucket。hash 先落到某个 bucket,bucket 里放若干 key/value。如果冲突太多,bucket 后面接 overflow bucket。查找时,如果主 bucket 没找到,就继续追 overflow。
Swiss Table 属于开放寻址。它不会先把冲突挂到另一条链上,而是在 table 的 group 数组里按 probe sequence 继续找下一个 group。每个 group 依然先看 control word,再决定哪些 slot 需要真正比较 key。

这两种结构带来的直觉完全不同。
旧模型里,你会特别在意 overflow bucket 多不多,因为那意味着更多额外对象和指针追踪。Swiss 模型里,你更该关注 group、probe、control byte、tombstone、table grow/split 这些概念。
所以,今天再讲 Go map,不能只把旧 hmap 图换个标题。你得换心智模型。
当然,Swiss Table 也不是没有代价。开放寻址依赖探测序列,删除时不能随便把 slot 标成 empty,否则后面的探测可能提前停止。于是它需要 tombstone。源码注释里也讲得很明白:如果删除的是一个完全满的 group 里的 slot,不能直接标 empty,可能要标 deleted;tombstone 通常会在 grow 时清理。
这就是底层数据结构里的真实取舍:
你想让查找路径更紧凑,就要接受删除、探测、增长逻辑变复杂。
性能从来不是白送的,只是代价藏在了更深的实现里。
Go 没有照搬 Swiss Table,它加了一层多 table
如果只是把 Swiss Table 搬进 runtime,事情还没完。
Go map 有自己的麻烦:它不能因为 table 需要增长,就让一次操作背上太大的停顿。传统 Swiss Table 在增长 group 数量时,probe sequence 会跟着变,很多 slot 都要重新排列。换句话说,一个 table 往往要整体 grow。
整体 grow 对小表问题不大,对大 map 就不舒服了。
Go 的改造是:顶层 map 不一定只有一个 table,而是由一个或多个 table 组成;用 extendible hashing 根据 hash 的高位选择 table。每个 table 自己仍然是一张完整的 Swiss Table,但它只负责一部分 hash 空间。
源码注释里的说法很直白:为了支持增量增长,map 会把内容拆到多个 table 里。单个 table 增长时,只影响 map 的一小部分。Go 还给单个 table 设了最大 capacity:1024。超过这个限制,不是继续把同一个 table 做大,而是 split 成两个 table。
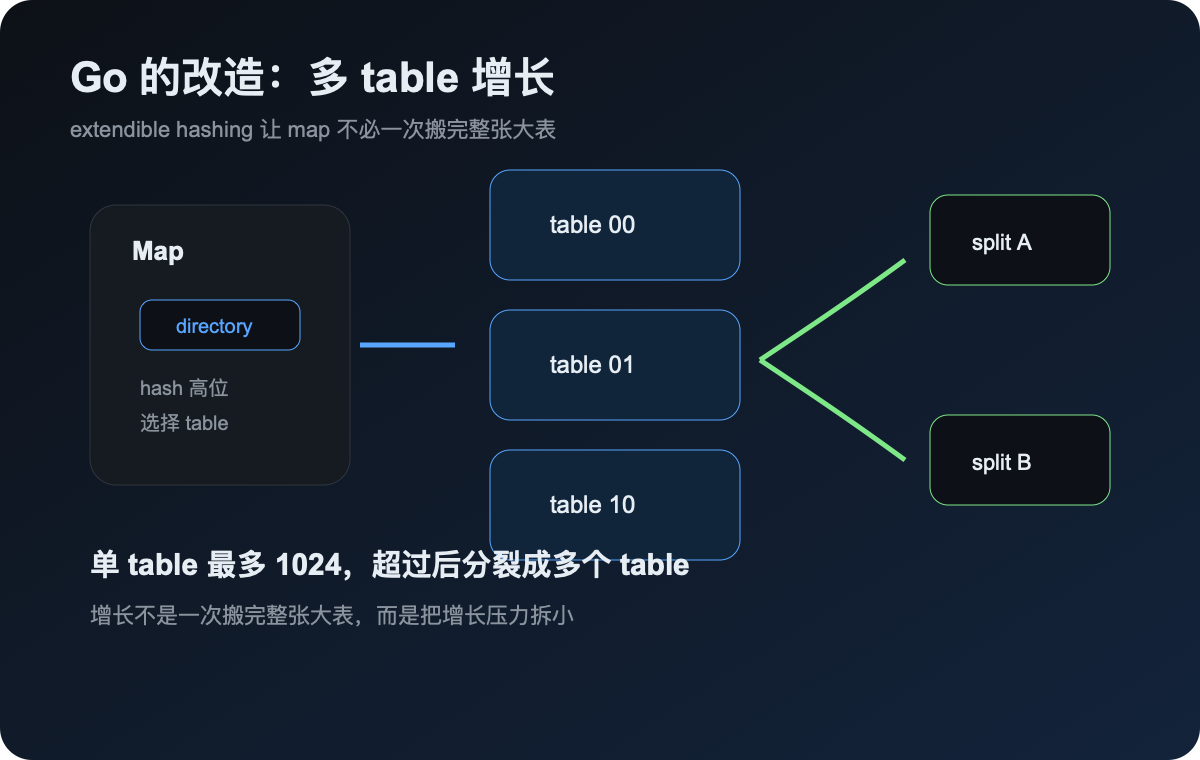
这个设计很关键。
它说明 Go 并不是单纯追求某个 benchmark 更漂亮。runtime 还要考虑增长延迟、迭代语义、GC、对象大小、不同 key/value 类型下的复制成本。源码里甚至在 maxTableCapacity = 1024 旁边留了 TODO,说这个值还需要在性能和 grow latency 之间继续调。
这类注释很有意思。它提醒我们:runtime 不是教科书上的完美结构,而是一堆工程取舍的现场。
Go map 的新实现可以概括成两层:
底层 table 用 Swiss Table,让单次查找更贴近 CPU。
顶层 map 用多 table 和 extendible hashing,让增长不要变成一次巨大的搬家。
这才是 Go 版 Swiss map 和普通 Swiss Table 之间最值得讲清楚的地方。
delete 删的是关系,不是容量
很多人对 map 内存的误判,来自一句过于省事的话:删除 key 就释放内存。
这句话太危险。
更准确地说,delete(m, k) 会删除这个 key 到 value 的关系,会清掉相关 key/elem。如果 value 间接指向一个很大的对象,删除 key 之后,只要没有别的引用,那个大对象当然可能被 GC 回收。
但 map 自己的 table 存储,不会因为你删了很多 key 就自动缩小。
Researcher 素材里有一个 map_delete_memory.go 示例。本机 Go 1.25.4 上,填充大 map 后 HeapAlloc 大约 288.8 MiB;把 key 全删掉,len 已经是 0,但 map 还活着时,HeapAlloc 仍然大约 288.8 MiB;直到把 map 变量设为 nil,再触发 GC,HeapAlloc 才降到 0.1 MiB 左右。
这不是说每个业务场景都会保留同样的数字。类型大小、逃逸、GC 时机、value 是否间接存储,都会影响结果。
但趋势值得记住:
delete 删的是关系,不是容量。
如果你有一个长期存活的大 map,曾经装过很多数据,后来删到很少,它仍然可能占着一大块 table 存储。想真正缩小,常见做法是新建一个 map,把仍然需要的少量数据搬过去,让旧 map 失去引用,交给 GC。
这不是每次 delete 后都要做的动作。多数普通 map 不值得折腾。但在缓存、索引、长生命周期对象里,这个边界要知道。
不理解这一点,你会在排查内存时盯着 len(m) 看半天,然后疑惑:明明长度已经很小,内存为什么还不下来?
答案是:len 不是容量,也不是 table 占用。
range map 的随机,不是 bug,是契约
Go map 还有一个老问题:遍历顺序。
很多人第一次踩坑,是测试里写了类似这样的断言:把 map range 出来拼成 slice,再和期望 slice 比较。今天过,明天不过;本机过,CI 不过。然后怀疑 Go runtime “不稳定”。
其实 spec 一直没有保证 map 迭代顺序。到了 runtime 实现里,Go 还显式做了随机化。Go 1.25.4 的 Swiss map 源码注释在 iteration 语义里写得很清楚:Iteration order is unspecified. In the implementation, it is explicitly randomized.
这不是小脾气,是语言契约。
map 表达的是 key 到 value 的关系,不表达顺序。你如果需要稳定顺序,就要自己拿 key,排序,再按排序后的 key 访问 map。
| |
序列化、签名、测试快照、配置输出,都应该这么处理。不要把“这次 range 刚好是这个顺序”当成任何承诺。
无序不是缺陷,是契约的一部分。
这也是为什么底层实现可以从 hmap 换成 Swiss Table,而语言层不需要改 API。只要 map 仍然满足语言规定的语义,runtime 就有空间继续优化它。
普通 map 不是并发容器
再补一个常见误区:Go map 在 runtime 里会检测一部分并发错误,但这不等于它是并发安全的。
Researcher 核查的 Go 1.25.4 源码里,map 读路径会检查是否存在写入,命中时 fatal:concurrent map read and map write。写入路径也会检查并发写,可能 fatal:concurrent map writes。
这类报错很多人都见过。它的价值是尽早把错误暴露出来,而不是替你做同步。
普通 map 的正确使用方式仍然很明确:
- 多 goroutine 只读,且没有并发写,通常没问题;
- 有读有写,用
sync.RWMutex或其他同步保护; - 读多写少、key 稳定、场景适合时,可以评估
sync.Map; - 也可以用单 goroutine ownership,把 map 操作收敛到一个拥有者里。
不要把 runtime fatal 当成安全网。它不是帮你“自动避免数据竞争”,它只是发现某些危险状态后直接让程序死给你看。
性能建议:别把 map 神化,也别拿 slice 硬扫到底
讲到 Swiss Table,很容易把文章写成一句话:Go map 更快了。
这句话太粗。
Researcher 在 Apple M1 Pro、Go 1.25.4 上跑了一组 benchmark。1024 个 int 的命中查找,map lookup 大约 5.2 ns;slice 线性扫描命中大约 293–296 ns。这个结果很直观:当集合规模上来,并且你是在按 key 查找时,map 的平均 O(1) 路径会明显压过线性扫描。
但这不代表 map 永远更快。
小集合、顺序扫描、热缓存、批量处理,slice 仍然可能更合适。slice 的优势是连续内存、结构简单、没有哈希成本。map 的优势是按 key 查找、去重、索引、动态关联关系。
真正有用的判断不是“谁更快”,而是:你的访问模式到底是什么?
如果你只是处理一小段顺序数据,别为了显得高级把它塞进 map。
如果你已经在 1000 个元素里按 key 找东西,就别拿 slice 从头扫到尾,还安慰自己“反正数据不大”。
还有一个实用点:如果你大概知道 map 会有多少元素,给 make 一个 hint。
| |
同一组本机 benchmark 里,插入 10,000 个元素,不给 hint 时分配 81 次,内存约 591 KB;给 hint 后分配 34 次,内存约 296 KB,耗时约降到三分之一。这个数字不是普适常数,但趋势很稳:你知道规模,就别让 runtime 盲猜。
不过 hint 也不是越大越好。给得离谱,只会提前占更多空间。它表达的是“我对规模有个合理预估”,不是“我想许愿性能变好”。
旧说法不是不能看,但要换成新边界
这篇文章不是要你以后看见 hmap、bmap 就皱眉。
旧资料仍然有价值。它能帮你理解 Go map 演进过什么,也能帮你读懂一些历史文章、老版本代码和面试题。但如果你写的是 Go 1.25 的默认实现,就不能把旧资料原封不动搬上来。
最容易出问题的,是下面几句话。
第一句:“Go map 冲突多了会挂 overflow bucket。”
更稳的说法是:旧实现里有 bucket 和 overflow bucket;Go 1.24+ 默认 Swiss map 走的是开放寻址和 probing,冲突处理已经不是这张图。
第二句:“Go map 的负载因子是 6.5。”
这句话同样要加版本边界。旧实现里可以这么讲,Swiss map 里更接近的心智模型是 group、control byte、tombstone 和 table 的增长阈值。Go 1.25 的 table.go 里已经不是拿旧的 6.5 当主角。
第三句:“delete 以后 map 内存会释放。”
应该改成:delete 会删除 key/value 关系,也可能让 value 指向的大对象被 GC;但 map table 自身不会因为 delete 自动缩小。长期存活的大 map,如果经历过大规模填充再删除,必要时要重建。
第四句:“range map 顺序随机,所以多跑几次总能稳定。”
这更不对。正确动作不是赌随机,而是承认 map 没有顺序。需要稳定输出,就拿 key 排序。测试、签名、序列化都一样。
这些修正看起来只是措辞,其实是在保护你的判断。技术文章最危险的地方,不是完全错误,而是少了版本边界。读者读完以后以为自己懂了,结果拿到新版本源码一看,底层已经不是那回事。
读者真正该带走的动作
如果你平时只是正常写业务代码,不需要每天想着 Swiss Table。Go map 的价值,正是让大多数人不用关心这些细节。
但有几件事值得立刻改。
写性能敏感代码时,如果你能估出规模,给 map 一个合理 hint:
| |
这不是玄学优化。它能减少增长过程中的分配和重排。但不要把 hint 当成越大越好的参数。估得离谱,只会让 map 提前占更多空间。
写测试和序列化时,不要直接依赖 range map 的顺序。先收集 key,排序,再输出。这个习惯比记住任何 runtime 细节都重要。
处理长期存活的大 map 时,不要只看 len(m)。如果它曾经装过很多数据,后来删掉大部分,内存仍然高,考虑重建一张新 map,把保留的数据搬过去。
做并发访问时,不要因为 runtime 会报 concurrent map writes 就觉得普通 map 有保护。那是失败信号,不是同步机制。该上锁上锁,该用 sync.Map 评估 sync.Map,该收敛 ownership 就收敛。
写文章或给团队做分享时,先写清版本:Go 1.23 及以前、Go 1.24+ 默认 Swiss map、还是 GOEXPERIMENT=noswissmap。少这一句,后面的图画得再漂亮,也可能是在讲错对象。
现在再讲 Go map,应该换一张图
如果你只记住一件事,就记住这个:Go map 的语言语义没变,runtime 心智图变了。
过去那张 hmap -> buckets -> overflow buckets 的图,还可以放在“旧实现对照”里。它不应该再站在 Go 1.25 默认实现的中心。
今天更应该放在中心的是这几个词:
- group:8 个 slot 是基本筛选单位;
- control word:用低 7 位 hash 和状态位快速筛候选;
- open addressing:冲突不是挂链,而是继续 probe;
- table:一张完整 Swiss Table;
- directory:多个 table 的入口;
- extendible hashing:用 hash 高位选择 table,支持分裂增长。
这套词不是为了显得你懂源码。它们会直接影响你怎么看性能、内存和旧资料。
看到有人还在用 load factor 6.5 解释 Go 1.25 默认 map,你就知道他讲的是旧模型。
看到有人说 delete 之后 map 内存一定会下来,你就知道他混淆了 value 回收和 table 缩容。
看到有人把 range map 的顺序拿去做测试断言,你就知道问题不在 runtime,而在他把无序结构当成了有序结构。
Go map 最容易误导人的地方,是它表面太稳定了。API 几乎没有让你感觉到变化,底层却已经从 overflow bucket 换成了 Swiss Table。
这正是 runtime 的工作:让你平时不用关心发动机,但在你需要打开机盖时,里面已经不是老样子。
map 的 API 没变,发动机已经换了。
下一次再看 Go map 文章,先看它画的是哪张图。