前面倒了三家,黄仁勋为什么还敢拿 ARM 撞 x86 的墙
x86 的墙不是硅片砌的,是四十年软件兼容性砌的。NVIDIA RTX Spark / N1X 这次真正的新变量,不是 ARM,而是 CUDA 和本地 AI 工作流。
Windows 想甩掉 x86,这条路上已经倒了三次。
第一次是 Windows RT。微软把 ARM 塞进 Surface,结果老 x86 软件一个都不让跑。用户买到手才发现,这台机器看起来像 Windows,真正能用的东西却少了一大截。
第二次是 Surface Pro X。微软学乖了,给它加了仿真层,让 ARM 假装自己是 x86。问题是,假装终究是假装。普通软件跑得别扭,驱动、安全软件、内核级工具更是直接撞墙。
第三次是骁龙 X Elite。高通这次硬件认真多了,续航、性能、Copilot+ PC 的声量都摆上来了。结果市场反应还是冷。不是没人看见它,是很多人看完之后,还是回头买了 Intel 或 AMD。
所以 NVIDIA 这次拿 RTX Spark / N1X 进场,问题不该是“这颗芯片快不快”。
前面三家死掉,没人是因为 PPT 上的性能数字不够漂亮。
真正的问题是:黄仁勋手里有没有一张前面三家没有的牌。
我觉得有。
但这张牌不是 ARM。
是 CUDA。
x86 的墙,不是硅片砌的
很多人讨论 x86,容易把它说成一套处理器架构。
这当然没错,但太浅了。
x86 真正厉害的地方,不是某一代 CPU 跑分更高,也不是 Intel 和 AMD 做了多少年芯片。它厉害在于,整个 Windows 世界有几十年软件都是冲着它写的。
财务软件、工程软件、游戏、插件、驱动、VPN、端点安全代理、企业里没人敢动的老系统,全都默认这台机器就是 x86。
你换一颗芯片,不是换一块硅片。
你是在要求整个软件世界重新适配一次。
这就是前面三次冲锋最难看的地方:它们不是输给了某个参数,而是输给了用户手里已经能跑的那堆东西。
x86 的墙不是硅片砌的,是四十年软件兼容性砌的。
Windows RT 死得最干脆,因为它干脆不让老软件进门。Surface Pro X 看起来聪明一点,靠仿真层翻译,但翻译慢、翻译不全,碰到内核级工具就露馅。骁龙 X Elite 终于把硬件做得像样了,可一旦进入真实工作流,用户还是会问同一个问题:我现在这些软件、插件、驱动、游戏、企业工具,到底能不能稳稳跑?
这个问题没有被解决之前,ARM PC 再省电,也只能先当“第二台机器”。
而大多数人不会为第二台机器掏高端主力机的钱。

NVIDIA 不一样的地方:它不是先卖 CPU
如果 NVIDIA 只是说:我也做了一颗 ARM CPU,它更省电、更轻薄、更适合笔记本。
那这篇文章就可以提前结束了。
因为这条路苹果已经走得很漂亮,高通也已经撞过一次。NVIDIA 再去拼续航、拼轻薄,本质上还是第四次拿 ARM 去撞 x86。
但 RTX Spark / N1X 更有意思的地方在于,它不是先拿 CPU 讲故事。
它拿的是一整套 AI 和图形工作流。
根据 researcher 交接中整理的 NVIDIA 官方口径,RTX Spark 这套平台包括 Blackwell RTX GPU、6,144 个 CUDA cores、第五代 Tensor Cores、最高 128GB unified memory、20-core NVIDIA Grace CPU、NVLink-C2C,并且面向本地 personal AI agents,官方说法里包括本地运行 120B 参数模型和最高 1M token context 这类能力。
这些数字当然吸睛。
但数字不是重点。
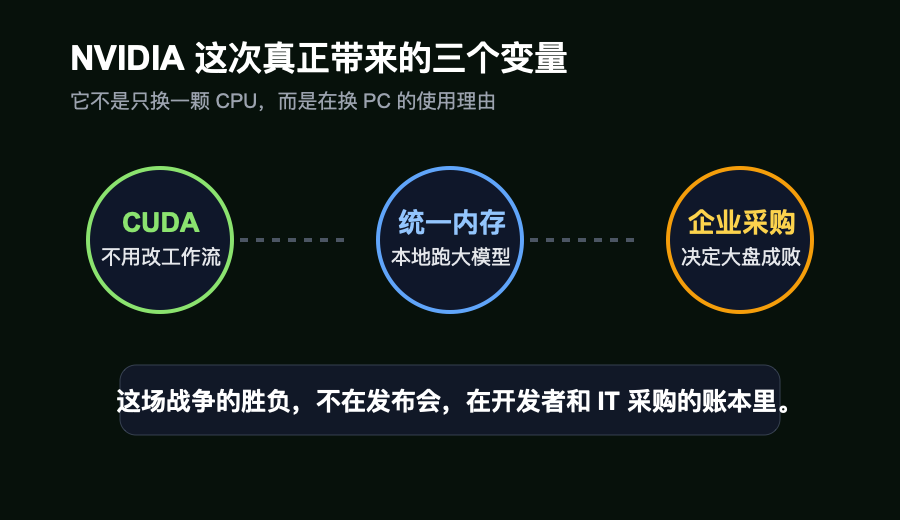
重点是 CUDA。
过去十几年,AI 开发者、数据科学家、做推理和高性能计算的人,已经把大量工具链长在了 CUDA 上。PyTorch、TensorRT、各种 CUDA kernel、推理脚本、模型部署流水线,不是说换就换的。
你让这群人换到苹果或高通平台,不是不可能。但他要重新适配,要经过中间层,要忍受工具链不完整,要处理某些库“理论支持但实际难用”的情况。
这些成本不会写在发布会规格表里。
但开发者每天都会遇到。
NVIDIA 这次真正想说的是:你过去在数据中心、工作站、独显 PC 上跑的那套东西,我把它塞进一台高端 Windows 机器里。你不用改习惯,不用换生态,不用为了本地 AI 重新学一套不成熟的工具链。
这才是它和前三次 Windows on Arm 最大的不同。
NVIDIA 不是拿 ARM 去撞 x86,它是拿 CUDA 去撬 x86。
这句话很关键。
如果用户只是想刷网页、写文档、开视频会议,那 ARM PC 的优势再大,也很容易被“我现在这台 x86 够用”挡回去。
但如果用户每天都在跑本地模型、调 CUDA、做图形渲染、写 AI agent,情况就变了。
他不是因为 ARM 更优雅才换机器。
他是因为这台机器可能让他少维护一台本地工作站,少租一部分云端算力,少在不同平台之间来回折腾。
这才是高端市场愿意付钱的理由。
统一内存,是本地 AI PC 最能讲通的一笔账
本地 AI PC 过去最大的问题不是“有没有 AI”。
而是模型装不进去。
传统 x86 笔记本里,CPU 有自己的内存,独显有自己的显存。你跑一个大模型,显存不够,就得在显存和系统内存之间搬来搬去。带宽、延迟、拷贝成本都会出来。
最后用户看到的不是架构问题。
是卡。
RTX Spark / N1X 把故事改成了另一种:CPU 和 GPU 共享一整块最高 128GB 的 unified memory,再加上 NVIDIA 自己的软件栈。对本地大模型来说,这个设计比“CPU 跑分又高了多少”更重要。
因为 AI PC 如果只会在云端调用模型,那它和普通 PC 的差别并不大。你多花的钱,最后还是买了一个“本地算力可能用得上”的想象。
只有当大模型真的能在本地跑起来,而且跑得足够顺,它才有新机器的理由。
这也是 NVIDIA 比高通更会讲故事的地方。
高通讲的是:这台 Windows 笔记本续航好、轻、安静,还有 NPU。
NVIDIA 讲的是:你的 AI 工作流可以搬到本地,而且不用离开 CUDA。
前者是在解释一台更好的笔记本。
后者是在解释一台新型工作站。
差别很大。
但它还没有赢,甚至离赢还很远
到这里,文章如果写成“x86 要完了”,就是被发布会带跑了。
NVIDIA 的新变量确实强,但它要面对的旧问题也没有消失。
第一个问题,是续航叙事和本地 AI 叙事互相打架。
ARM PC 一直喜欢讲省电、轻薄、全天续航。这个卖点成立的前提是,机器大多数时候能闲下来,能低功耗待机。
可本地 AI agent 的想象恰好相反:它在后台持续看、持续算、持续分析、持续执行任务。
如果 AI 一直干活,机器就不可能一直省电。
这不是 NVIDIA 一家的问题,而是整个本地 AI PC 叙事的问题。你不能一边说它永远在后台替你工作,一边又让用户相信它始终像普通轻薄本那样省电。
本地 AI PC 最大的敌人,可能不是性能,是电池和价格。
第二个问题,是普通用户到底需不需要。
开发者、AI 工程师、数据科学家、内容创作者,确实可能为本地算力买单。因为他们能把时间、隐私、云端成本、工作流稳定性算成钱。
但普通用户不一定。
如果云端 AI 已经够用,如果每天只是写邮件、查资料、做 PPT、开会,那他为什么要为 128GB unified memory 和本地大模型能力多付一大笔钱?
这不是“用户不懂先进技术”。
这是用户很会算账。
技术公司最容易犯的错,就是把开发者的兴奋,当成大众市场的需求。
第三个问题,是企业采购。
高端 PC 真正的大盘,很大一部分不在个人玩家手里,而在企业 IT 的采购表里。这里的逻辑非常冷:稳定、可管、兼容、少出事。
企业不怕机器不够酷。
企业怕的是 VPN 不能用、端点安全代理没适配、老驱动出问题、某个工程软件在仿真层下性能掉下来、某个内核级工具直接跑不起来。
个人用户遇到问题,可以折腾。
企业 IT 遇到问题,就是工单、事故、合规风险和采购责任。
所以别看发布会上讲得热闹,企业端不会因为几句“AI 原生 PC”就大规模切架构。
发布会负责点火,企业 IT 负责浇水。
这一盆水,往往浇得很准。
这不是“英伟达稳赢”,而是 x86 的防线第一次被换了打法
这里要把话说得克制一点。
NVIDIA 手里有 CUDA,不等于它已经拿下 PC。CUDA 在 AI 开发者那里很强,在普通办公室用户那里未必强。一个销售、财务、人事、行政员工,不会因为 CUDA 原生支持就换电脑。他关心的是 Excel 宏能不能跑、打印机驱动会不会闹脾气、公司 VPN 能不能稳定连上。
这也是 x86 防线最烦人的地方。
它不是一堵正面城墙,而是一堆细小、陈旧、分散、没人愿意重新碰的门槛。每一个门槛看起来都不高级:一个老插件,一个行业软件,一个安全代理,一个打印驱动,一个十年前写的内部工具。可企业采购真正怕的,正是这些“不高级”的东西。
所以 NVIDIA 这次最可能先拿下的,不是整个 PC 市场,而是一个高端缝隙:AI 工程师、内容创作者、数据科学家、想在本地跑模型的开发者,以及愿意为 CUDA 工作流买单的专业用户。
这个缝隙如果足够大,它会慢慢撬动生态。
如果不够大,它就会变成又一个昂贵的小众玩具。
苹果能迁移成功,不代表微软也能
很多人会拿 Apple Silicon 说事:苹果都能从 Intel 迁到 ARM,Windows 为什么不行?
这个类比只对了一半。
苹果迁移成功,当然靠 M1 足够强,也靠 Rosetta 2 做得好。但更关键的是,苹果有一个微软和 NVIDIA 都没有的东西:控制权。
硬件它做,系统它做,开发工具它管,应用商店它管,生态规则它说了算。
苹果可以给开发者下最后通牒:你跟不跟?不跟,就等着被新平台甩开。
Windows 世界不是这样。
Windows 世界里有太多 OEM 厂商、老软件供应商、企业内部系统、硬件外设、行业工具、驱动开发者。微软和 NVIDIA 不能像苹果那样直接发一道圣旨,让所有人整齐转身。
它们只能一边砸钱,一边给工具,一边求开发者适配,一边用新需求慢慢拉。
这就注定了 Windows on Arm 的迁移会更慢、更乱,也更容易半路卡住。
NVIDIA 有钱,有开发者影响力,有 CUDA,有 RTX,有数据中心光环。
但它买不到一件事:时间。
软件生态不是靠一场发布会迁过去的。
它只能靠一个个真实用户、一个个真实软件、一个个企业采购周期慢慢迁。
更大的棋,不只在笔记本
如果只盯着 RTX Spark / N1X 这一台机器,会把 NVIDIA 的野心看小。
消费 PC 只是边缘战场。
更大的战场在数据中心。
NVIDIA 这几年真正想做的,不只是卖 GPU,而是把 AI 计算的整套系统都握在手里:GPU、CPU、互联、软件栈、开发者生态、整机方案。Grace、Vera Rubin 这条线,瞄准的是数据中心里原本由 Intel Xeon 和 AMD EPYC 占着的位置。
这才是 x86 阵营真正紧张的地方。
如果 NVIDIA 只是在消费端做一台贵笔记本,Intel 和 AMD 当然会防守,但不会立刻被改命。
可如果 NVIDIA 在数据中心继续把 CPU 也纳入自己的 AI 系统里,再在高端 PC 端用 CUDA 和本地 AI 工作流培养用户习惯,那它挑战的就不是某一代 PC 芯片。
它挑战的是 x86 在“通用计算默认入口”上的地位。
这件事短期不会完成。
但方向已经变了。
以前 ARM PC 挑战 x86,是说:我也能做 Windows 笔记本,而且更省电。
现在 NVIDIA 挑战 x86,是说:AI 工作流正在变成新的入口,而这个入口默认站在我这边。
这就是为什么这次值得看。
不是因为 x86 明天就会倒。
而是因为第一次有人拿另一堵软件墙,去撞 x86 的软件墙。
接下来一年,看三个数就够了
这场仗不会在发布会当天分胜负。
也不会靠某个跑分视频分胜负。
接下来一年,真正要看的只有三个信号。
第一,原生软件数量。
尤其是 AI、创作、工程、游戏相关的软件,愿不愿意给 Windows on Arm 做认真适配。只靠仿真层,它永远是“能跑但不放心”。原生软件越多,说明它越能从 x86 的旧兼容性里独立出来。
第二,企业试点。
不是某个博主买一台试用,也不是展台上跑一个 demo,而是大公司 IT 部门愿不愿意批量试点。VPN、端点安全、设备管理、驱动、老软件,这些硬骨头如果啃不下来,NVIDIA 再会讲 AI PC,也很难拿下真正的大盘。
第三,OEM 持续出货。
看 ASUS、Dell、HP、Lenovo、Microsoft、MSI 这些厂商,是不是只做一波高端尝鲜机,还是愿意在后续产品线里持续押注。如果 2027 年下半年大家悄悄把高端 Windows 机型又换回 x86,那发布会再热闹也没用。
所以,黄仁勋这次能不能撞开 x86 的墙?
我的判断是:它不会立刻推倒 x86,但它确实找到了前三次没有找到的撞法。
前三次拿 ARM 撞 x86,撞的是兼容性。
NVIDIA 这次拿 CUDA 撞 x86,撞的是开发者的下一代工作流。
这比单纯拼续航更危险,也更现实。
但最后买不买账的,不是黄仁勋台下的掌声。
是开发者愿不愿意把项目搬过去,是企业 IT 愿不愿意把采购单签下去,是 OEM 愿不愿意连续两三代继续做下去。
这三个数不会出现在发布会金句里。
但它们会给出答案。